
OS-9
大体框架:

文件属性、文件分类只需要略微记忆即可,稍微注意下文件分类中的形式

注意的是,文件名只在open系统调用的时候使用,后续都只使用其标识符
无结构文件别名“流式文件”,有结构文件别名“记录式文件”
文件控制块FCB包含控制文件的一系列信息,类似于PCB进程管理块
FCB的有序集合被称为文件目录,简单来说就是FCB1、FCB2、FCB3、FCB4…这样一串
一个FCB自然就可以被称作是一个文件目录项,通常由FCB组成的文件目录也视作文件
FCB自然有其的一些特有信息,书上有,重视下创建时需要为文件创建其FCB
理解上可以用FCB列表来理解,一个个列下去
FCB是目录文件中的内容,其中包含了文件所在的物理地址等信息
打开文件表中包含的是该文件的表项,也可以说就是FCB,从磁盘调入内存,方便使用
注意区分:
打开文件表存在的目的是方便一个打开文件的写、读、删等操作的实现,不必再去找磁盘
放在内存里,就不必每次都去文件目录里检索这个文件的目录项在哪
目录项和索引结点分离的目的是,减少检索时的开销,加快检索的速度,要区分开
简单来说就是把检索所需要的信息单独列出来,这样检索就可以更加高效
索引结点和一般文件表项结构上:
FCB文件目录—FCB—文件
文件名表项—索引结点—文件
打开文件表:
进程打开文件表—系统打开文件表—FCB—文件
索引结点是FCB的改进版,将文件名和FCB的其他信息相互分离
此时文件目录只包含文件名(此文件名是对应的用户看到的文件名)和索引号
目的是为了减少检索时不必要的调用开支,因为每次检索文件名都需要调入文件目录
采用FCB的目录,明显冗余信息过多,因而单独提取使用的文件名来检索
索引结点内存放其他信息,可以分为磁盘索引结点和内存索引结点,分别包含一些内容
需要注意的是,内存索引结点并非将文件调入,而是将其类FCB的索引调入方便后续查询
内存索引增加的内容基本都是为了进程的存在而服务的
文件操作:
在书上的程度进行一些补充说明,首先其均是操作系统提供的系统调用
创建过程中,一方面是分配外存,另一方面是创建一个FCB//索引结点//文件目录项
删除需要先查,再删除目录项//索引结点//FCB,同时释放内/外存中该文件占用的空间
整个系统只有一张系统打开表,每个进程都有自己的打开文件表用于存储私有信息
当一个文件处于打开的状态,为了减少每次读、写的检索时间,才采用了打开表
这样就能实现保存了该文件的外存地址,不必每次都去外部检索该地址,只需要访该地址
同时只要已经被其他进程使用过即已经检索过,其他进程也可以直接指向系统表即可
不必主动再次检索,系统表内不会新增,只会在进程表内新增
打开的过程:
1.根据文件存放路径找到相应的目录文件,从目录中找到文件名对应的的目录项
并检查该用户是否有指定的操作权限(操作权限存放在文件目录项中
2.将目录项复制到内存中的“打开文件表”中,并将对应表目的编号返回给用户
之后用户使用打开文件表的编号来指明要操作的文件
对于关闭文件,设置了一个计数器,只有当计数器完全为零是才允许删除,存于系统表中
读、写细节补充,课后习题里面也有:
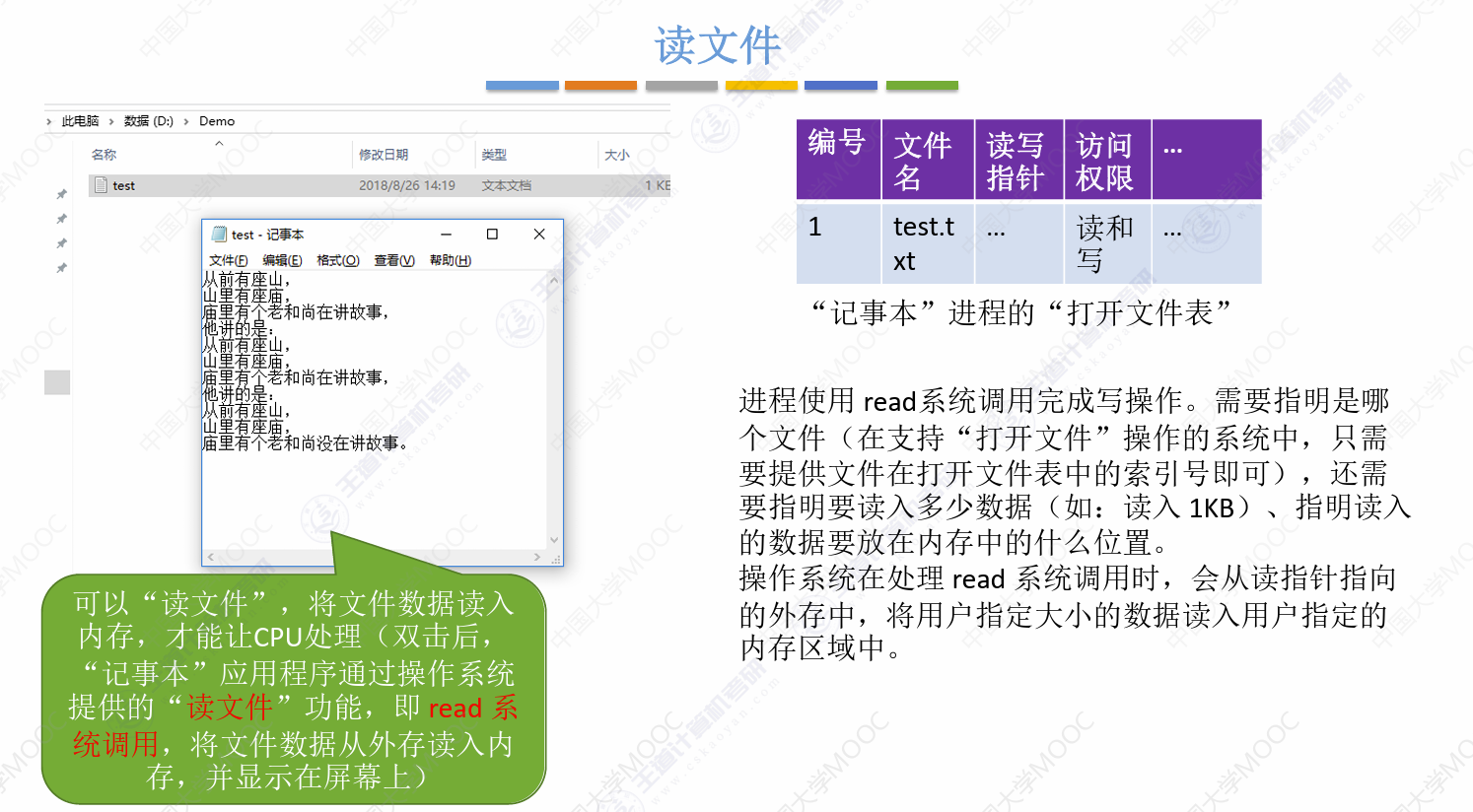
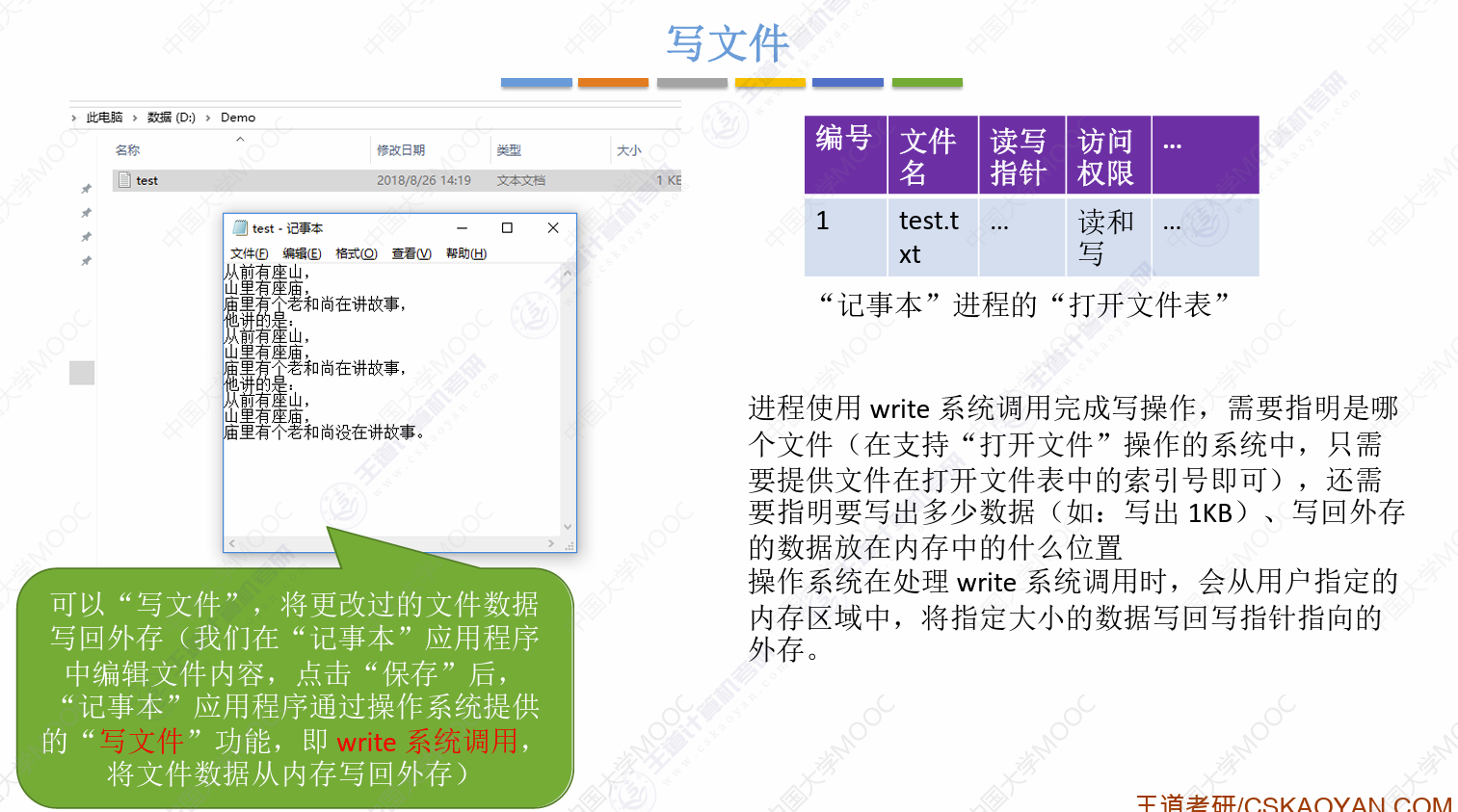
文件保护补充:
口令密码需要和日常区分,没有对访问类型控制进行任何的限制,只限制了访问
口令就是字母意思,密码是因为只需要解码、译码所以比较费时间
精简的访问控制“精简”在了对用户的处理,以“组”进行分配,将庞大用户群分为组
按组分配访问控制权限
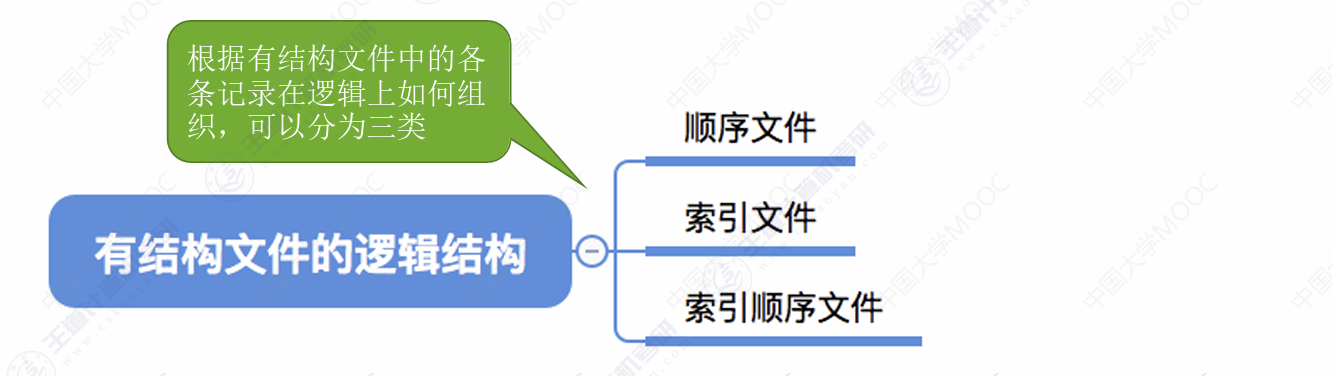
文件逻辑结构、物理结构以及混淆点总结:
无结构文件也被称为“流式文件”,关于定长、不定长的补充说明


三种文件模式
索引号一般都是可以默认不需要显示存储的,因为索引表一般是顺序连续存储的
例如变长顺序索引文件中的文件表,其索引号就是可以不需要显式的
显示链接分配中的FAT文件分配表中的盘块号也是可以隐含的,因为通过数组来实现的
一般通过数组来实现的,其就可以以A[0]直接取即可,其顺序号可以直接隐含
自然,顺序文件的读取也是可以直接隐含读取的,因为本就是数组结构
顺序文件:
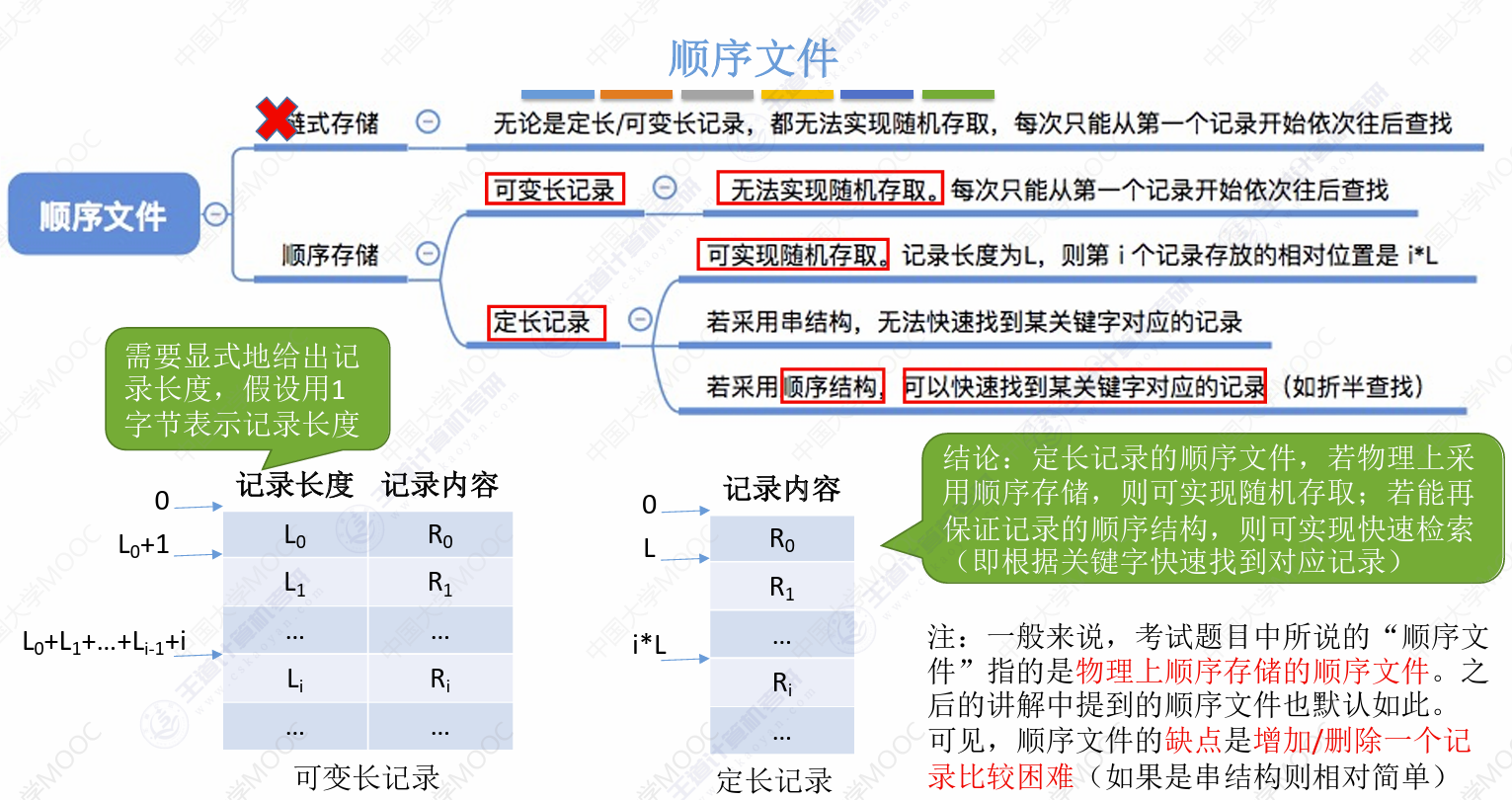
然后这边看到边上的字,这边说的是,考试中说的顺序存储指代的是物理上顺序
需要注意的是,这边的链式存储、顺序存储均是逻辑意义上的存储方式
例如,不论数据结构到底是链表还是顺序表,他们都采用分配在一块连续逻辑区域数组上
顺序表各个数据项可以通过数组下标访问其下一项、支持随机访问、次序访问
但链表只能是单向走的,为了得到下一项,必须要遍历前N项,因而说是不可随机访问
数组在逻辑上也是连续的,所以这一切都只是逻辑上的分配、处理
因而他们和物理上的存储手段几乎是无关的,物理上要处理的是数组怎么存储的事
这一节这部分内容所说的“地址”也均是逻辑地址,而非物理地址,有困扰
单纯在顺序文件中,可变长记录只能一个个访问,但后续的两种策略,其就可以随机访问
定长均是可以随机访问的,无非在随机访问的基础上,如果实现了顺序结构那么可快查
顺序文件顺序存储顺序结构,妙啊,顺序文件也有其适用范围,书上有写
索引文件,就是为了满足顺序文件变长记录的随机访问的,为其增加一个索引表
附:索引表可以不唯一
为每一项变长记录增加一个索引表,相当于用一个新数组,A[0]代表第0个记录的地址
把变长变成了定长,但需要明白的是,这个索引表也是占内存的,这些和表目录暂时无关
单纯是逻辑上对文件的实现,这些都属于逻辑结构,是属于数据结构,和底层无关
索引顺序文件:
将“变长记录顺序文件”中的所有记录分为多个组,一组记录对应一个索引表项目
例如And/Anaconda/Anti/Auto分为一个组,But/Because/Become/Bit分为一个组
组内可以无序排序,但一个组内的分组依据必须要有,类似于以某个字母开头
或者也可以采用以某个字母结尾,在实际数据库应用里面还可以采用以学号等作分组依据
组间也可以随意排序,反正是顺序查找,组之间的排序依靠一个“代表”实现区分
代表即为这个组的首元,例如A组就是And,B组就是But
索引表可以按关键词排序,也可以不排序,如果按关键词排序那么就是顺序文件顺序结构
可以折半查找
相对前两者而言,检索次数总体减少了很多,这个要会计算
同时多级索引文件也需要会计算其查找次数,其平均查找次数课后综合题有写,建议观摩
哈希,这边的地址说的是逻辑地址,不是物理地址,可支持随机查找
连续分配、链接分配、索引分配(单级、多级、混合)均是对上述“数组”的存储方式
也就是上层采用的无论是什么模式,说白都离不开一块抽象连续的存储区域“数组”实现
下层需要实现的就是对数组具体在内存中怎么存储的实现,这里就需要联系到表目录
不同的实现方式,表目录是不同的,因为涉及到实际的内存分配
磁盘一般采用“块”的方式分配,和主存的块一般大小一致,一般都会有内部碎片存在
簇的思想是把多个块当作一个块来处理
连续分配就是单纯的,分配一块物理上连续的区域
这时候每个文件的表目录项只有文件名、起始位和最终结束位,一般默认采用了索引结点
毕竟FCB本就是落后淘汰的选择
这时候说的访问地址,一般就是直接在说物理地址了,可以随机访问、可以顺序访问
至于优缺点,这里只对缺点稍微谈一下:
连续内存空间的要求比较高,有时候甚至都不能完成,即使磁盘空间足够的情况下
例如空闲有1、1、1,需要3个连续空间,即使磁盘空间够,也无法分配,分配了就有外碎
在文件修改的时候,是需要物理上移动的,例如拓展如果空间不够就需要物理向后移动
链接分配,分为隐/显两种分配方式,两种均对应离散型磁盘空间分配法,有空间就可装
隐式的目录组成是文件名、开始项指针、结束项指针,其实就是单链表的物理存储逻辑
内部每个磁盘项都会有向后一块的指针,用户必然不可见,因为是底层的
用户可见的是其自己设置的链式存储方式中,这个链表指针是可见的,和这个不同
缺点、优点见书,对簇进行一些解释
簇实际上相当于扩大了块的大小,仅此而已,把多个块当作一个块
因而分配磁盘的时候,一个文件也是分配一个簇,而不是以块,那么浪费就会增加
其访问是需要多次磁盘I/O的,因为总体是一个链表,只能顺序去访问
一个1KB的文件,占用4个4KB的块组成的簇,内部碎片大量增加自然能理解
显式的特征就是Fat文件分配表,整个磁盘里面只会有一个,并且加载后一直驻留内存
此时的文件目录只有文件名、起始块号,而Fat表内存储相应该块号的下一块是哪块

由于这个表是驻留在内存里面的,所以未来的查询只需要访问这个表,不需要访问磁盘
这个算是比较重要的点吧,毕竟磁盘的访问变成了访存的次数,两个都可以作考点
相对而言访问磁盘的数量肯定大幅度减少了


其支持顺序访问、随机访问,物理层面上的,内存中的随机访问
相对而言上述两种方式都是物理上有一定联系在,例如链式物理间用链连起来
但索引就真正没关系了,物理存储可以随意,具体的索引顺序,即数据顺序可以任意改变
因为只需要在内存中的索引表中修改即可,完全不会涉及物理上
例如插入、删除,隐式链式是比较麻烦的,需要去反复找到其前驱并且读、写磁盘
而索引表就比较方便,只需要改变一下索引表的结构,稍微移动添加/减少就行
显示链式也比较方便,只需要改变内存中Fat就行,不需要回到原先的物理结构去修改
索引式:
在上述Fat思想下的进一步优化,只调入Fat表内的该文件对应的盘号而别的不需要调入
Fat是整个磁盘只有一个,因而代表其含有所有磁盘的对应下一块记录
因而占用内存也会较大并且还需要长时间驻留内存,但实际上用到的并没那么多
索引式将文件和其相应的索引块打包,当需要调用文件的时候,再把索引块给扔到内存
也就是一个文件对应一个索引表,这一点要注意,但索引块具体多少个,需要看情况
平时磁盘是需要存储这个索引块的
有时候也会把这个索引块称作是一个索引表,问题不大
当单级无法满足整个文件的索引时,就需要想办法拓展,而采用链肯定是最不明智的
因为链导致了各个索引块之间变成了链式,只能顺序访问,必然导致效率下降
所以就考虑使用多级索引,而多级索引对小文件不友好,因而产生了混合索引法
逻辑地址随机访问:定长顺序、变长索引、散列哈希
物理地址随机访问:连续分配、索引分配、显示链接分配
仅连续分配是固定连续区域分配,其余均是离散型分配
下面的内容总体总结不深,后续会进一步完善
关于计算:
多层索引的访磁盘次数,计算访问表项

需要注意的是,每次的查询表项都需要先把这个表给读入内存,再去查找
尤其要注意“顶级索引表”是否调入内存,统考常考,磁盘I/O也会因此有些变化
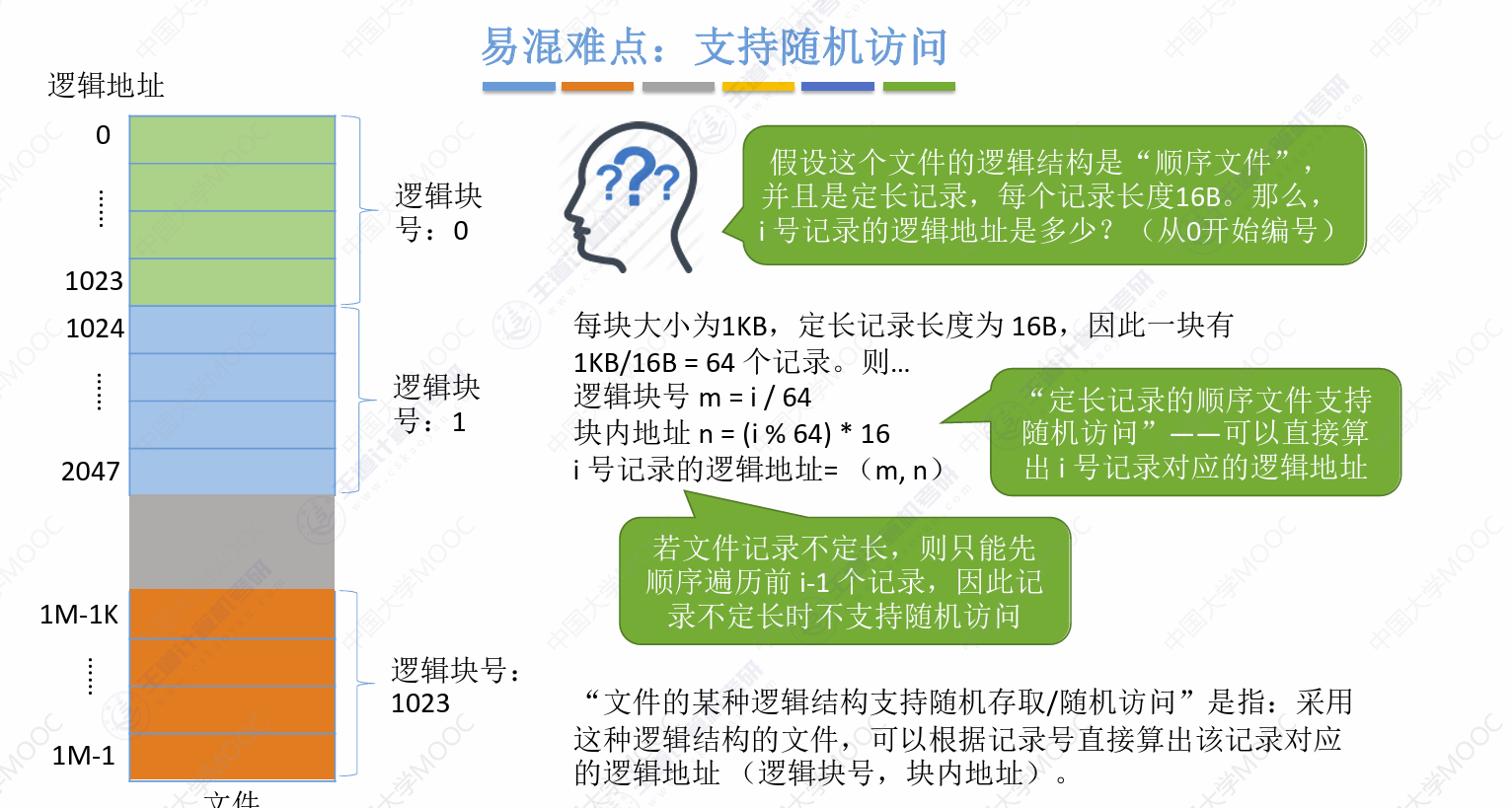
随机访问的逻辑号计算:
可以参考页表那边的计算,比较类似,16i/块大小=块号,16i%块大小=块内地址
混合索引计算,只需要明确直接、多级之间的关系即可
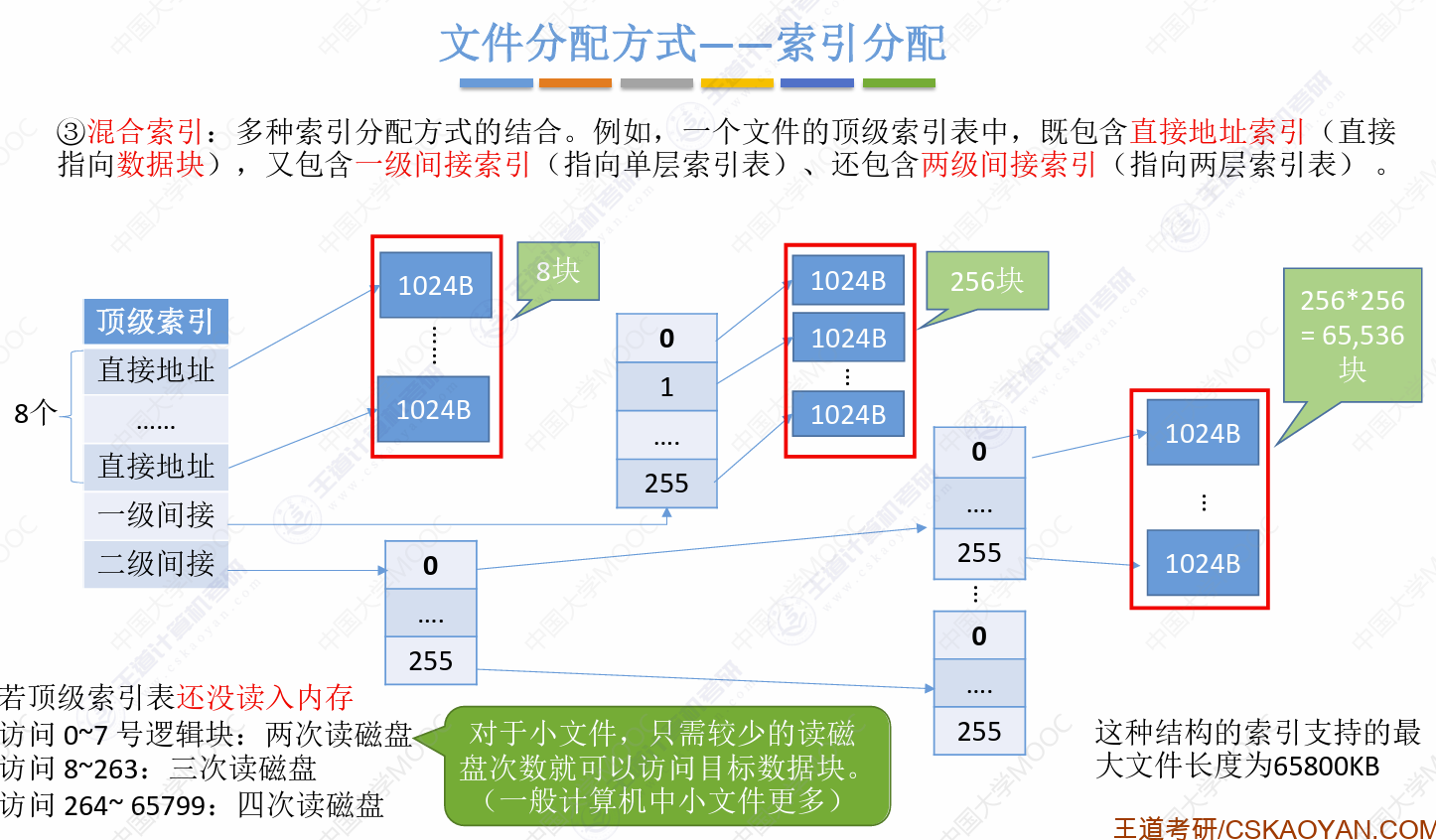
需要注意的是,其到底声明的是查询第XX块,还是查询前XX块,两者访磁盘次数不一样
因为文件是分离存储的,所以一旦要访问前XX块,那么就要加上前面的访问
例如本例中访问整个文件就需要10次磁盘I/O,因为每一节都需要考虑在内去访问
对多级索引的补充:
顶级表是否调入内存,影响的是其下一级表是否可以直接获得
如果顶级表没有调入内存,那么需要调入顶级表,然后才能根据表项得到下级表位置
从而从磁盘该位置把下级表引入内存
对于该步骤的一些补充和说明,以课后P289为例子
这里比较特殊,说的是“根目录第一块常驻内存”,而usr表项在第二块内…
所以需要先读入root表第二个块,读到对应的usr表项,一次I/O
再根据表项读入usr表,一次I/O
读入usr表项第一个块,这里面没有所需表项,但只能一个个查询去读,一次I/O
读入usr表项第二个块中所需表项you表,一次I/O
根据you表项读入dir表,一次I/O
这时候就已经能够从dir表中读到A的物理地址起始了,就算已经找到A了
其实个人觉得是比较容易混淆或者少数几次的,确实有点麻烦
理解上面可以从间接寻址理解,先读入地址,再根据地址读入这个表,再读表内地址
根据磁盘对应地址读入表,再根据表项的磁盘对应地址读入表,一个循环
另外就是,顶级表–>一级表—>二级表—>三级表—>数据块,容易混淆,有笔记在
P291
