
OS-7
三种装入方式:
本质是地址转换方式的不同
绝对装入:
仅支持单道批程序环境下的产物
内存中仅支持放一个程序,程序的逻辑地址和实际地址完全一致,不用转换
该地址可以被程序员、编译程序所赋予,对应的内存分配策略是单一连续分配
静态可重定向装入:
其特征是为作业分配一块连续的、固定大小的、固定区域的空间
在后续整个程序运行过程中一直保持固定大小,不会变化
地址在装入主存后直接转换为物理地址,相对地址转物理地址,不必使用地址转换机构
对应的内存分配策略为固定分配策略或者静态分配策略
动态可重定向装入:
别名动态运行时装入,其特征是为作业分配一块可不连续、不固定大小、不固定区域空间
在后续程序运行中可以根据实际所需变化空间大小,动态申请内存
地址装入主存后依旧保持逻辑地址,只有在运行的时候才会把逻辑地址转为物理地址
需要地址转换机构的协助,或者说重定位寄存器的服务
对应的内存分配策略是动态分区分配(连续分配),页式、段式、段页式(非连续分配)
三种链接策略:
静态链接、装入时动态链接、运行时动态链接
静态链接是在运行之前或者说装入之前,就全部完成打包不再拆开
对应的模式是:静态可重定向、固定分配策略,早期计算机系统
装入、运行时动态链接:
边装入边链接//只有要用到了才链接
对应的模式是:动态可重定向装入策略、段式、段页式(主要是段式逻辑,页式没体现
静态可重定向、绝对装入,以及相对应的固定分配、单一分配不需要地址转换机构
因为对静态可重定向/固定分配而言,其地址在装入内存后就已经是实际物理地址不必转
内存管理是不可视、透明的,是操作系统实现的,进程和上层只能看到物理地址
地址转换完全由硬件实现,操作系统只做辅助的缺页处理、寄存器值更新等辅助操作
中间的取值、比较、查询都是硬件自己完成
但对于整个转换过程而言,那么是操作系统和硬件共同完成的
勘误,上面的内容难免会有些错误在,参考后文博客,会有较进一步解释
进程映像可能配合C语言的代码一起考,未理解透彻,包括课后的某习题
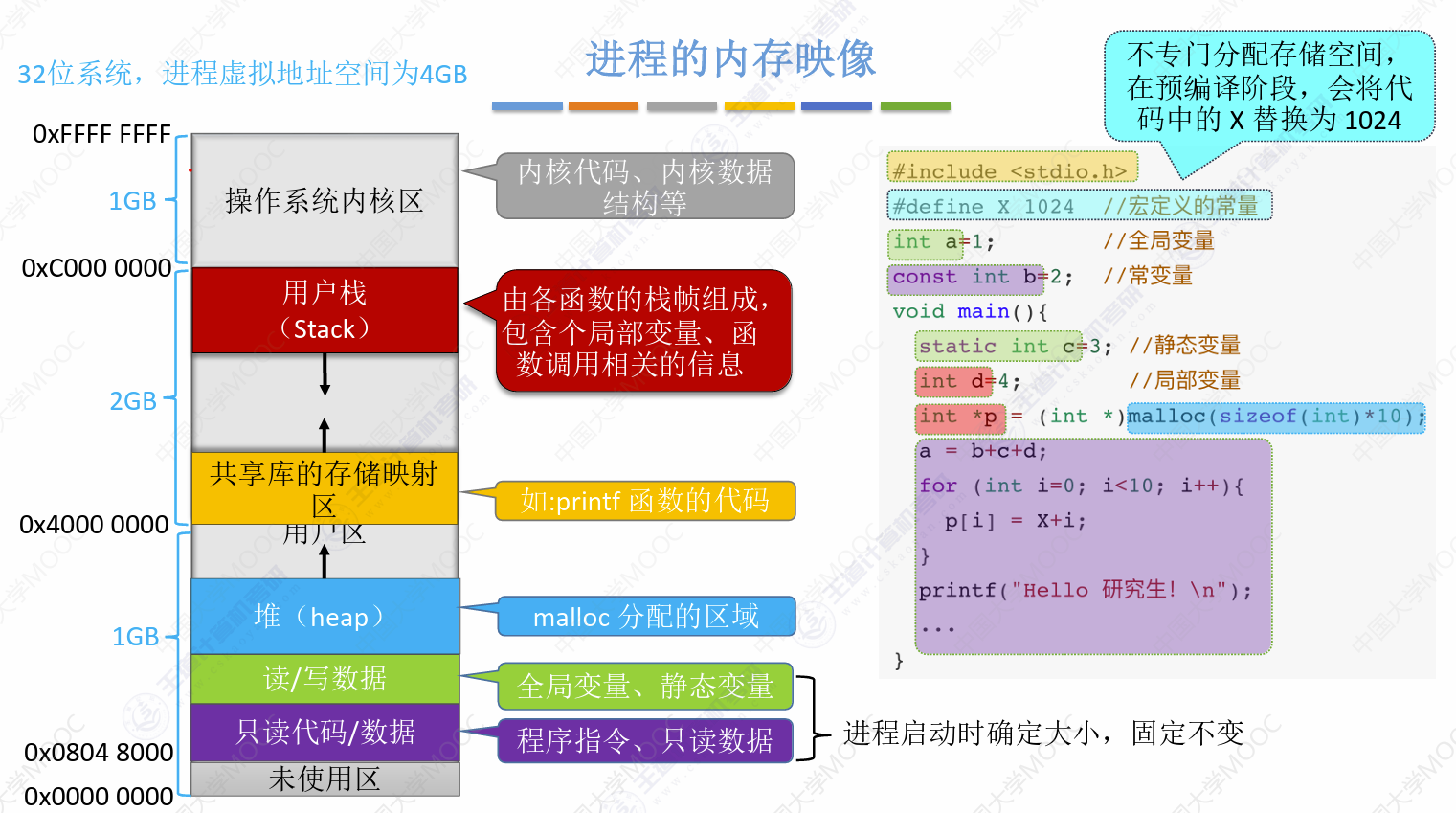

内存保护的目的是防止进程随意扰乱其他进程(用户进程扰乱OS进程或者扰乱用户进程
策略有CPU寄存器、重定向寄存器两种
CPU寄存器那句话描述不准确,这里给出解释:
在CPU中设置一对上、下限寄存器,存放进程的上、下限地址
进程的指令要访问某个地址时,CPU检查是否越界,由CPU来判断是否越界
每个CPU一对,或者说每个核一对,因为进程是并发运行在核/CPU上的
重定向寄存器、界地址寄存器,将复合在CPU内的寄存器单独拿出来当作一个模块
页式仅需要对比一次,段式需要对比两次,段页式也需要对比两次
往往也是一个CPU/核一个,无非不需要CPU做判断,同时寄存器的更新由OS来完成
因而对其的修改是特权指令
内存共享,无非就是页、段式的比较,后面会讲,页式不擅长共享,段式擅长
连续内存分配模式:
单一分配,对应上面的单道批,不会考,仅供了解
固定分区分配
最重要的就是三个点:分区大小固定、分区位置固定、分区是连续的
各个分区之间的大小倒不一定相同,会产生内部碎片
注意内部碎片的算法是块内还剩下多少空闲空间,5.2MB,1MB一块,0.8MB碎片
动态分区分配,对应:分区大小不固定(运行和装入时均可变)、分区连续
至于分区到底是不是固定的,这个是装入策略需要考虑的事情,和内存分配关系不大
会产生外部碎片
内部碎片:指一个进程实际占用的空间小于分配给其的空间造成浪费,固定分配会出现
外部碎片:指内存中,无法被分配的小碎片空间,一般出现在动态分区分配中
页表是不会产生外部碎片的,因为其是按照固定大小分配
段表是不会产生内部碎片的,因为其是按照动态分区策略来分配
分区回收策略:
前面有空的,只修改前面的分区大小为两者之和,合并
后面有空的,修改后者分区的大小为两者之和,开始地址为前空闲开始地址
两边都有空的,习惯前面的分区大小为两者之和,合并
分区分配策略:
首先明确,不管是什么查询结构,其空闲区的数据结构均是空闲分区链表结构
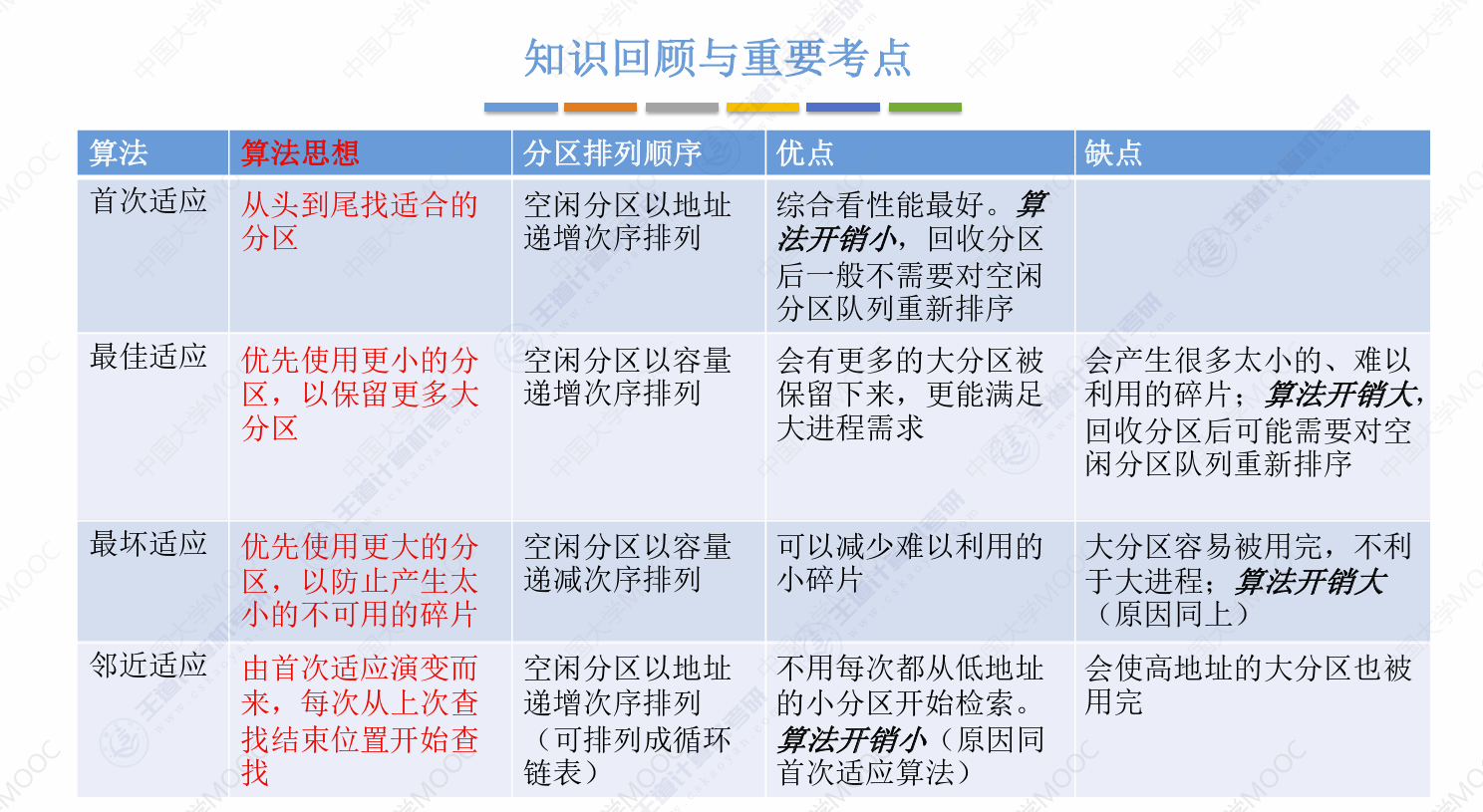
顺序查询有四种:
首次适应,按地址递增排序链表,找到第一个符合的分区
邻近适应,循环查询,任何区域的分配可能性都一样
最佳适应,按容量大小递增排序,找到第一个最小的符合要求的分区
最差适应,按容量大小递减排序,找到第一个最大的符合要求的分区
各自的优劣:
索引搜索:
一个索引表,多个空闲分区链,对应三种策略,不细谈,太过于复杂
页、段均是离散型内存分配策略,都对应程序的可移动,只能采用动态装入法
页式基本:
目的在于提高内存的利用率、实现离散分配
主存逻辑分块为多个页框,进程逻辑分块为多个页面
一个进程分为多个页,每个页被存在不同主存页框中,页表是连续的,一个进程一个页表
页表中存储了页号以及其对应的主存页号,以此完成地址映射
CPU给出的需要转换的逻辑地址结构为页号+页内偏移,一般默认字节编址
页表项内只有主存相应实际页号,拼接到原偏移量得到物理地址
页式地址变换:
地址变换机构只需要对页号进行判断是否超出该进程的最大页号,页内偏移不可能越界
进程的页表长期被存放在内存PCB中,但仅有需要调用的时候寄存器才设置其起始、长度
不管用不用,只要这个进程没有被挂起还在内存中,那么页表就一定在内存中
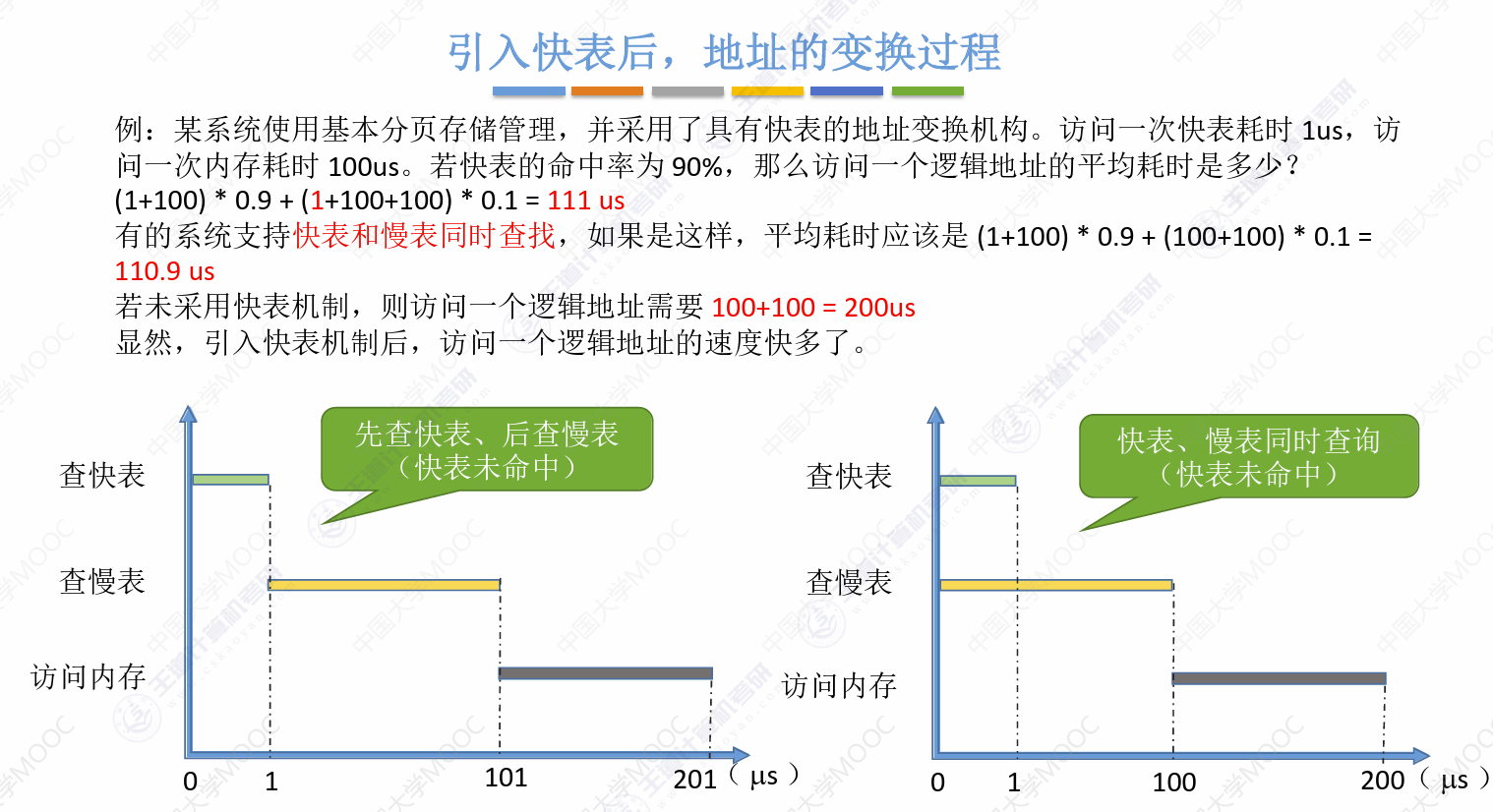
快表的引入和Cache的引入目的一样,快表命中用快表,快表没命中去主存里面找
减少访存次数是其核心,至于快表命中后,其实是先到Cache里面,然后再去主存里找
关于计算,个人认为参考个人的笔记即可,书上的例子非常杂乱,没有看的意义
或者自己找后面的真题、相应例题做一遍就能理解,书上的例题都是默认字节编址的
二级、多级页表的计算相关
页表是连续的,当得知主存内的页数以后,就可以依据每个页表能分配多少个页表项算
2^36=2^9·2^9·2^9·2^9,四个页表实现
同时需要知道一个事情:
主存的页数是必须要被完整表示的,所以意味着多级页表其实也就是在表示这一些页框
为了不让页表占用太多的“连续”内存,所以才产生了多重页表
但实际上多重页表本身反而会占用更多的内存、更多的系统开销,访存次数也会增加
例如N重页表,那么就会访存N+1次
注:理论上,页表项长度为3B即可表示内存块号的范围,但是,为了方便页表的查询,
常常会让一个页表项占更多的字节,使得每个页面恰好可以装得下整数个页表项
快表、慢表同时查询法:
易混淆概念:
页框、页帧、物理块基本是描述主存中所分的“块”
页、页面基本是描述进程自身被分成的“块”
相对应的页帧号、页框号、块号,页号、页面号也是针对这两者区分而言的
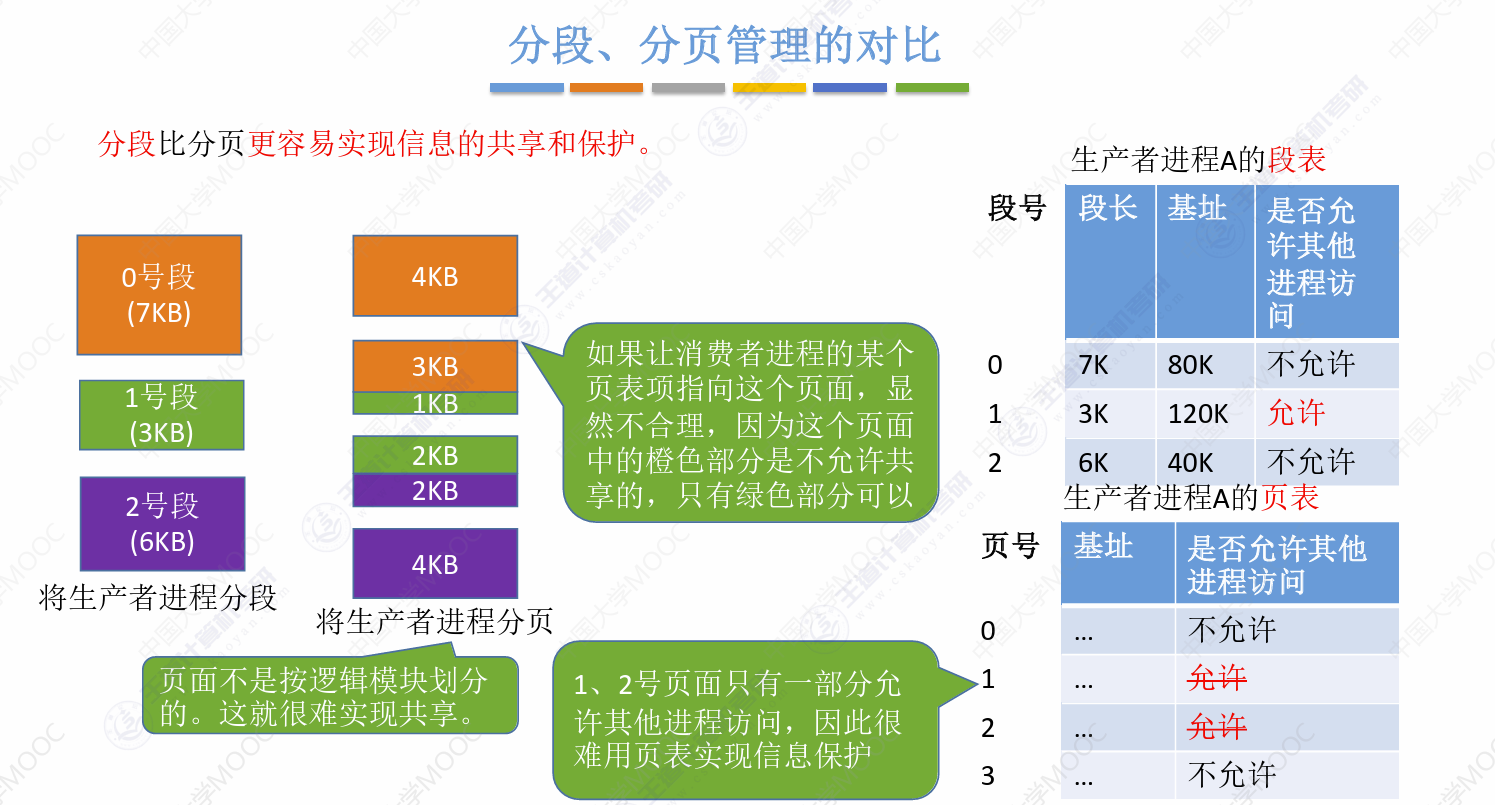
段式存储的优点解释:
方便编程,主要含义是可以按照编程代码的逻辑去进行分段存储
分段共享,指代的是一个共享代码区,或者说可重入代码,当代码区较大的时候
用页式时需要用多个页表项来指明其位置
但若使用段式,不论多大的代码都只需要一个段,只需要一个段表项就足够
分段保护,就是下面这个情况,如果用段式,那么很容易就能实现共享的保护
动态增长,这个就是指代段式的特性,即段的长度在运行过程中也是可变的(需要勘误
注:不太确定具体到底是运行可变还是不变的
动态链接,这个的解释见下

段式存储:
目的在于,实现上面所说的优点,按照用户的逻辑来分段而不是依靠操作系统的页分
常规的页分是硬件、操作系统完成的,用户完全不可视
但分段是用户、上层可视的,因为本就是为了这部分的需求产生的
逻辑地址分为:段号、段内偏移量
段表项内容分为:段号、段长、段基址
判断其是否越界需要判断两个,一个是段号是否越界,一个是段表长是否越界
一个进程对应一个段表,段表同样放在内存中,也可以引入快表
段内连续,段与段之间不需要连续
PS:段、页、段页那边写的很一般,后面会补充,以及覆盖与交换该节
