
计组8
局部性原理的本质实际上是对CPU预测的一种解释
空间局部性是指CPU会对这个数据周围,尤其特指数组、向量、指令集等集合数据提前预读
为了定义这个周围,往往采用将主存分块(地址上虚拟,解释方法不同分块)
然后将这个周围的数据放在Cache里面
时间局部性是指CPU会对循环内的当前执行的这个数据进行存留,以备下次的继续使用
包括循环内执行的指令、操作数,基本都会进行存留,下次取用的时候也就会方便一些的
这些都会存于Cache中,通过预测方式得到了高命中率
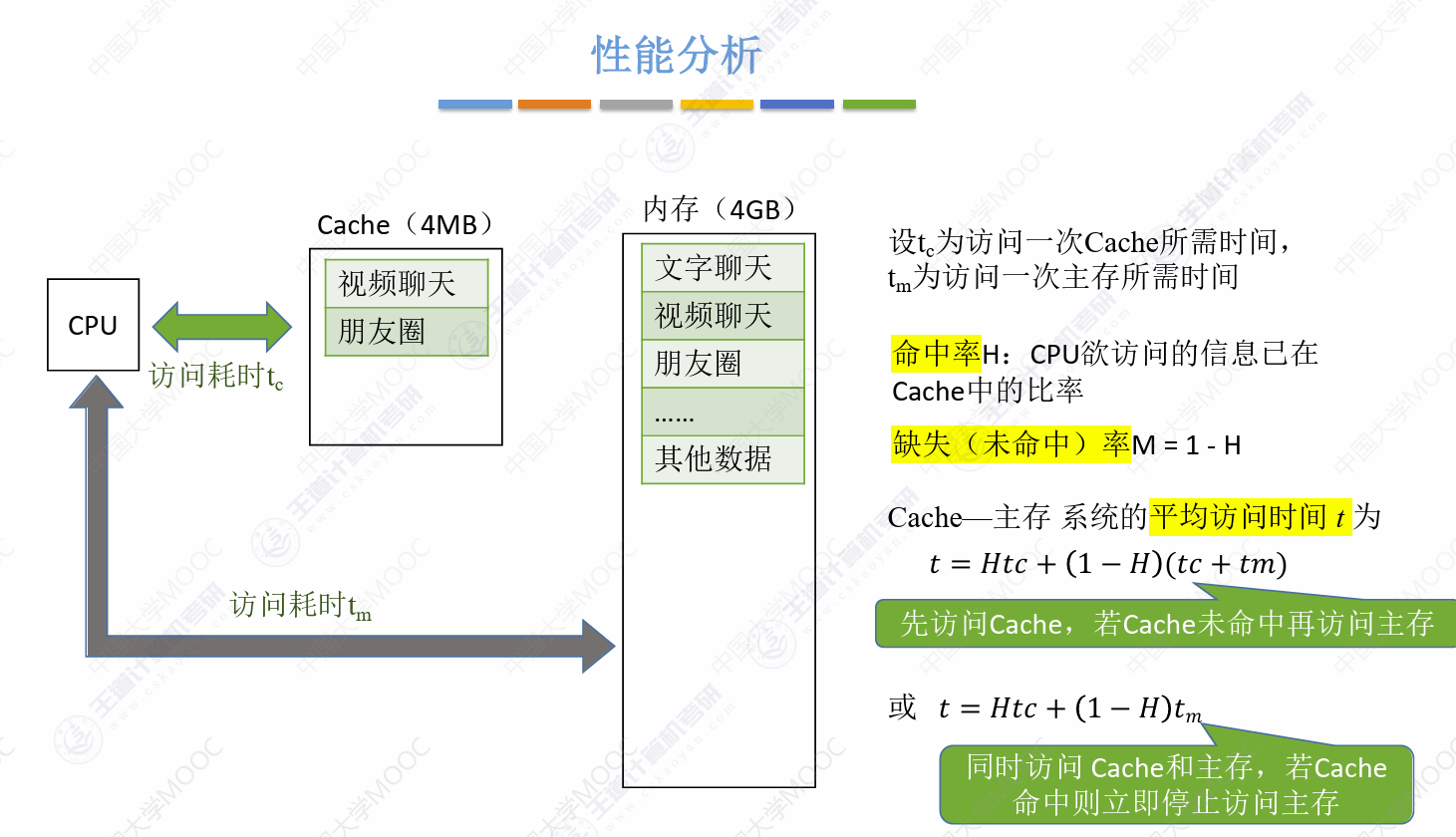
另外,性能分析那边,又到了文字游戏:提高了多少,提高了几倍,提高到几倍….

比较器么,书上写的比较模糊,但大致上应该是在说这样
直接映射是一个就够了,全相联就要N个,而组内就只需要组内可能是其存放的数量R个
一个块,可能在Cache里面存放在多少个位置上,就要多少个比较器
PS:
主存的块被称为“页、页面、页框”,Cache的块被称为是“行”
然后说几句吧,即使是块内,也是有多个地址对应多个数据行存储的,所以才要组内地址
主存和CPU交互是以机器字,而和Cache交互是以块为单位
主存地址是不会改变的,只是CPU在根据不同的映射法对应解释为不同的意思罢了
这里谈下一个容易混淆的点,主存地址、Cache位数
首先明确下,主存在三种不同映射模式下的地址解释方法,注意是解释方法
直接映射:标记位+行号位+组内地址
全相联映射:标记位+组内地址
N路组相联映射:标记位+组号地址+组内地址
然后再说下这几个怎么算
一般会给定主存的物理地址长度,所以总长往往是能够确定下来的
按某种编址方式,意思是多少位作为一个存储单元的大小,字节就是8位一个单元
字就是一个字一个单元,然后这样一个存储单元分配给一个地址
一个块大小给出以后,那么除去一个存元的大小就能得出有多少个存元一块
自然也就得出了需要多少位二进制才能分配完这N个存元的地址
如32B一块,按字节编址,那么就是8个存元,那么就是3位二进制地址,三位组内
注意下,因为主存块和Cache块大小是一样的,因而给定哪个块都能算出来
然后再说相对应的行号、组号,这个就是分多少行,多少组的问题了
对直接映射就是有多少块,然后需要多少位二进制来表示那么多个块,32块就要5位
对组号,就是求出Cache一共有多少组就行,例如二路,32B一块,64KB数据大小
那么就可以分为2^11块,2^10组,那么组自然也就占了十位,直接映射反正没有这个位
然后在算出上面两个以后,自然就得出了主存物理地址中对应的标记位长度
然后再谈Cache的位数组成,一般谈的是总容量,数据大小是单纯的块大小·块数
有效位+脏位+LRU替换位+标记位+数据位(32B就是32·8=256位,这里谈的是以bit作单位
有效位一位,必有,脏位仅当采用回写法的时候会有,一位
LRU替换位,直接映射肯定是没有的,因为直接映射是直接替换的,不考虑替换位存在
只有全相联和组相联会有,一般是logN(N是一组有多少个)
而一般只出现于组相联中,全相联据目前状态来说还没有谈过,但应该是视作一整组
另外就是标记矩阵的行需要和一般Cache中谈的行(也就是块,相区分
Cache中谈一行那么肯定就是在谈这样一块,不会有更多的歧义
但标记矩阵中就不一定,一行可能是多个标记位,例如组相联那么一行就有组号个标记位
全相联一行就会有N个标记位
这里谈几个点:
首先就是主存内分块是按照Cache中块的大小分的,不是按数量分的
再就是,按XX编址意味着每X位作一个存储单元,且每个地址单元对应一个地址
这里要和地址位数、存储位数区分开,存储位数是每个存储单元存储了几位数据,就是位
地址位数是指这个地址需要多少位二进制才能表达
这样看确实是,按什么编址,一个存储单元就有多少位
256MB大小,按字节编址256M个单元,每个单元8位,需要256M个地址,28位地址/地址线
按字(32位字)编码就是64M个单元,每个单元32位,需要64M个地址,26位地址/地址线
Cache的容量和总容量之间有一定的差别
同时按XX编址,得知了每块的大小后,自然可以得知每块的块内地址占几位
将主存分为N个块以后,对应地址的剩余高位实际上均在表示是第几块
替换算法:
目的是为了解决主存访问后需要把其内容放入Cache但Cache已经满的问题

大致上就这一些算法,其中考最频繁的是最后两种,前面的两种都因为运行效率较差不用
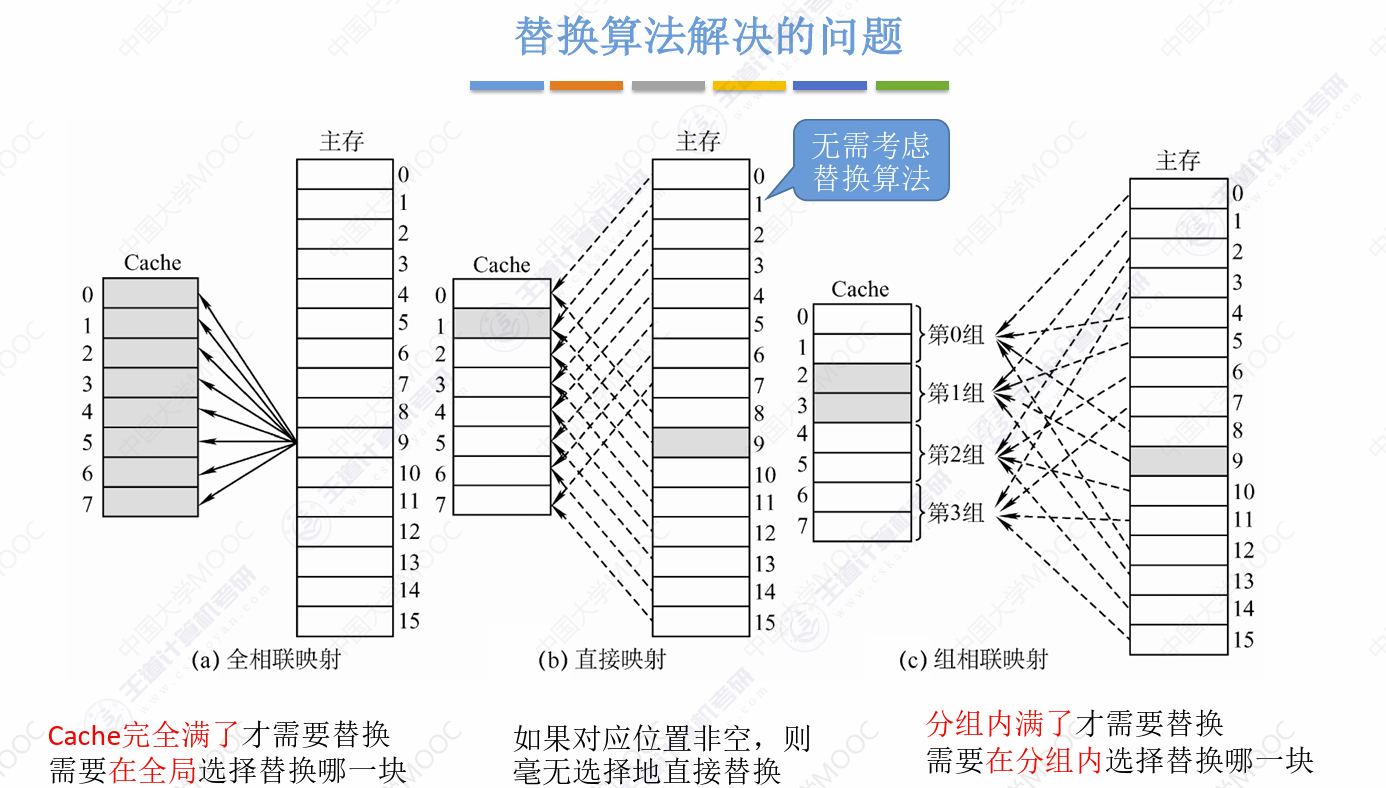
替换算法只会在全相联、组相联两个里面使用
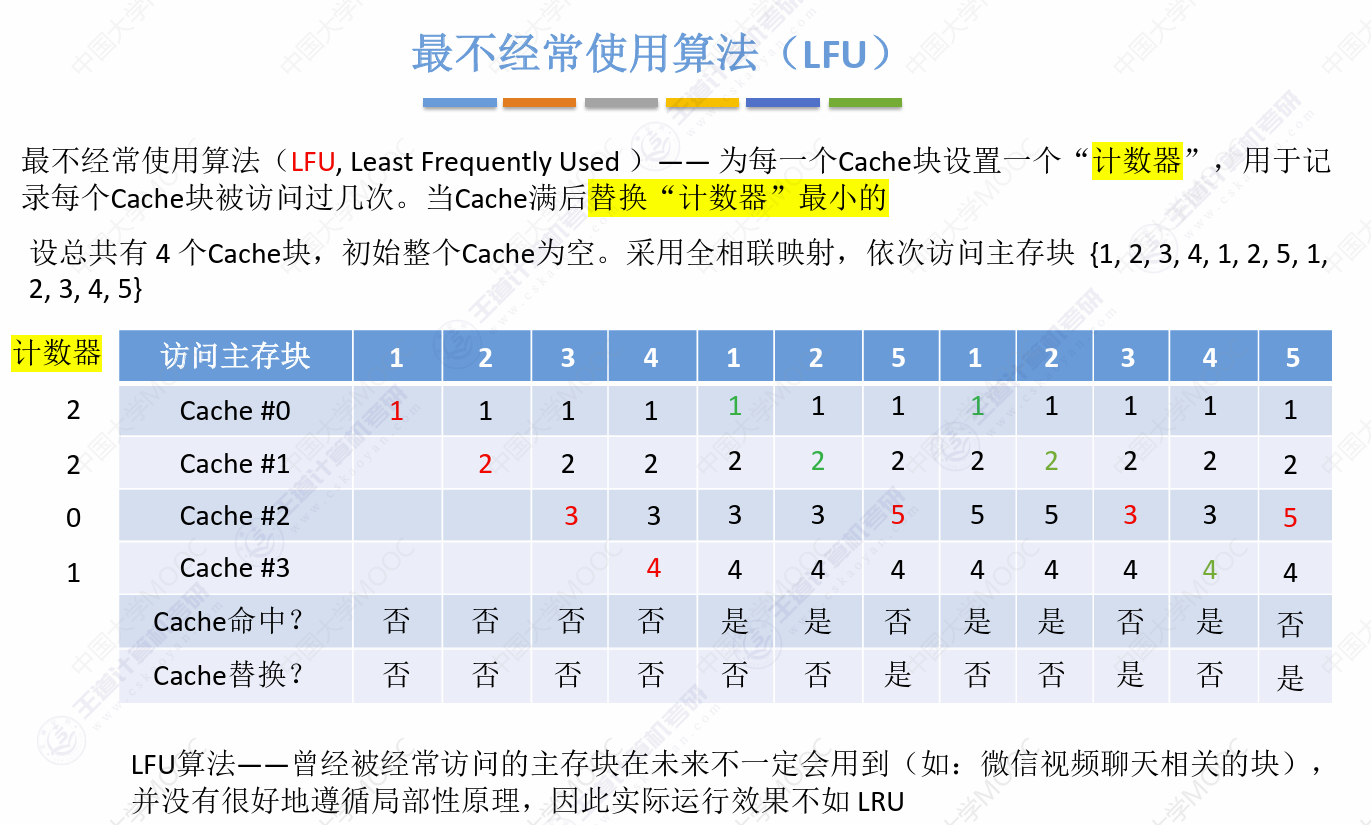
最不经常使用算法,理解为记录这个Cache块被访问了多少次,替换最少访问次的
这里如果产生了相同的使用频率最低块,那么可以采用FIFO或者行号递增等策略去选择
例如相同的0、0两个使用频率块,淘汰谁?
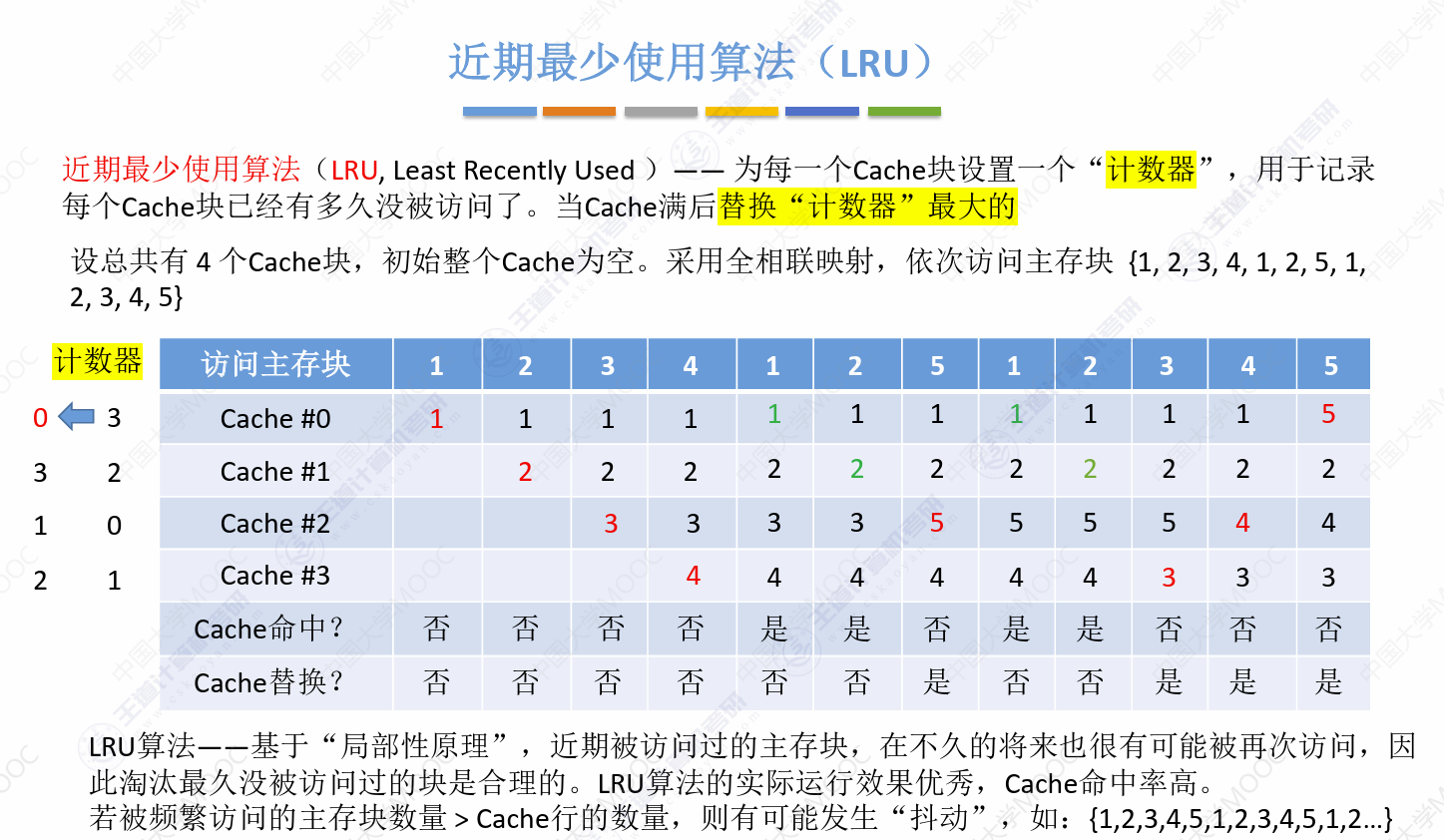
近期最少使用算法,理解为每一个Cache块的计数为“已几个周期没有使用”
每次自然替换的是计数值最大的
抖动的含义,以“1/2/3/4/5/1/2/3/4/5..序列访问,会反复刷新掉频繁使用的块,本质原因是Cache块太少了
全写法:
在每次写数据的时候同时把数据写入主存和Cache里面,那么替换块就不需要再写到主存
这里的缓冲区应该这样理解,CPU访问主存是很浪费CPU时间的事情
所以采用一个缓冲区,让CPU直接写到缓冲区里面去,因为CPU访问缓冲区很快
然后缓冲区再慢吞吞去访问主存,相当于把这部分CPU可能会浪费的时间交给了缓冲区做
提高了CPU的资源利用率
写回法只更新Cache中的数据,不把块中数据写入主存,只有替换的时候一次性写到主存
剩下就是比较麻烦的一堆组合了
写分配法搭配写回法的时候:
当没有命中的时候,就会先把主存内容送到Cache里面,然后在Cache中写,不改主存
同样,当写命中的时候也是直接在Cache里面写,不改主存内容
只有这个块因为读或者写被替换出去的时候,才把这个块所更新的内容一次性写到主存上
写分配法搭配全写法的时候:
当没有命中的时候,就会先写/修改主存内容,再把内容送到Cache里面
当命中的时候,就会同时修改Cache和主存中的内容
非写分配法搭配另外两者就不会有变化:
如果不命中的情况,那么只更新/修改/写主存单元,不会调入Cache中
如果命中,回写法,那么就会只对Cache内数据进行修改/写/更新
如果命中,全写法,那么会同时对Cache、主存内的数据进行更新操作
其实也可以看出,写回法比较适合搭配写分配法,这样就可以高效且保持替换更新性
全写法则比较适合搭配非写分配法,保留对主存内容的随时正确性
读不命中、写不命中均有可能会产生替换
读不命中是一定会把主存的内容写到Cache里面的,所以读不命中一定会有替换(满的时候
但写不一定,只有写分配法会把主存内容写到Cache中可能替换,非写分配法不会替换
