模型训练过程中,显存开销主要来源:
模型参数显存、激活显存、优化器状态、梯度显存
其中模型参数显存只同参数规模有关,优化器状态和梯度显存只和训练参数量相关
激活显存则主要同模型参数规模、计算图、输入数据大小等相关
激活显存往往是模型训练过程中占比最大的,其同输入数据长度、内部维度等因素相关较大
梯度显存则往往同参数显存相等,优化器状态取 Adam,则为梯度显存的两倍
激活显存主要用于计算梯度,若计算梯度时不需要该激活显存,则会被系统自动释放
前馈过程中只有模型参数显存、激活显存
反向传播过程中才会出现梯度显存、优化器状态显存
注:Adam 由于需要保留上一轮结果来计算本轮,因而其在第一轮训练后会常驻显存
注:反向传播过程中,激活显存会逐渐释放
参考文章:
常规梯度的计算策略
PyTorch显存可视化与Snapshot数据分析
这里为三个实验,通过实验可以验证一些事实:
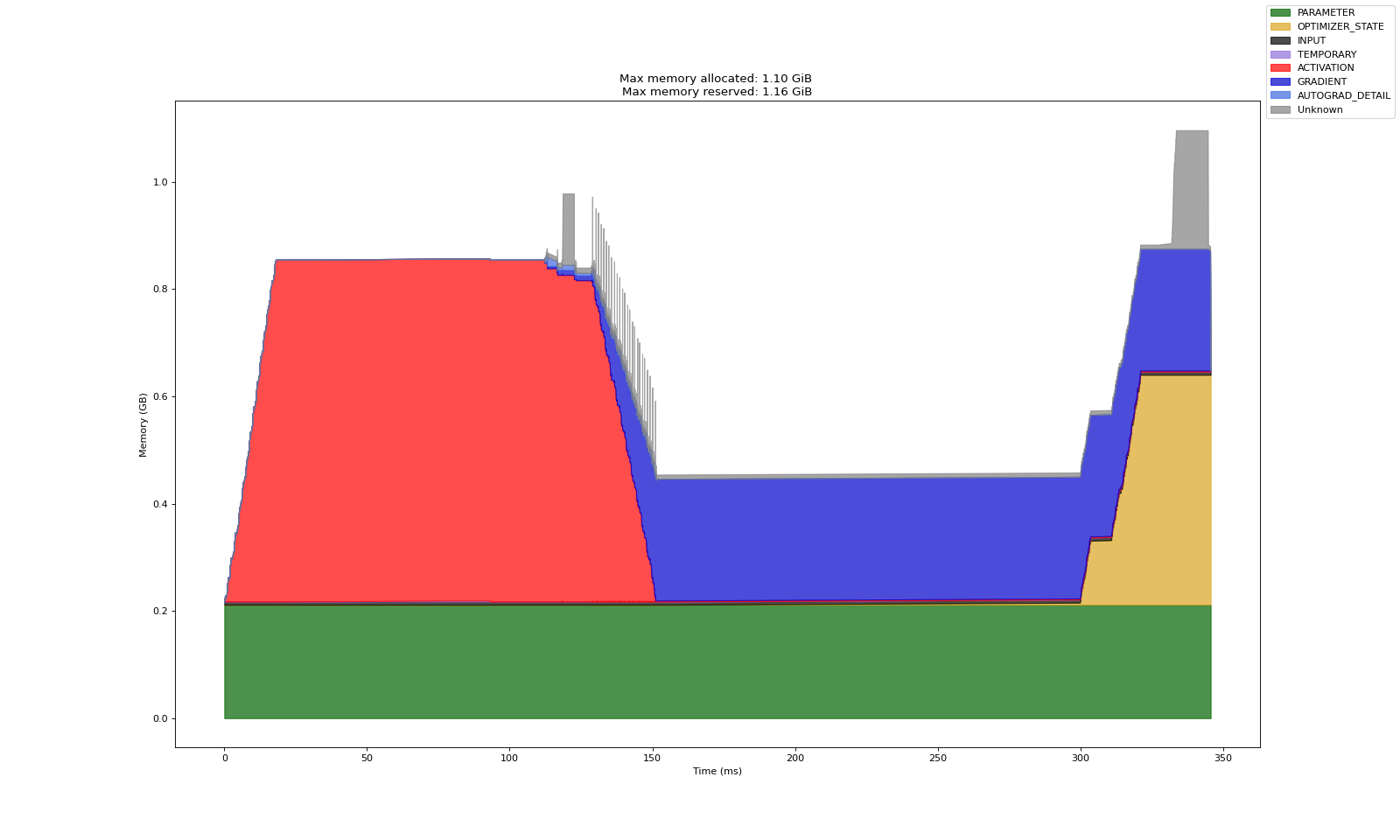
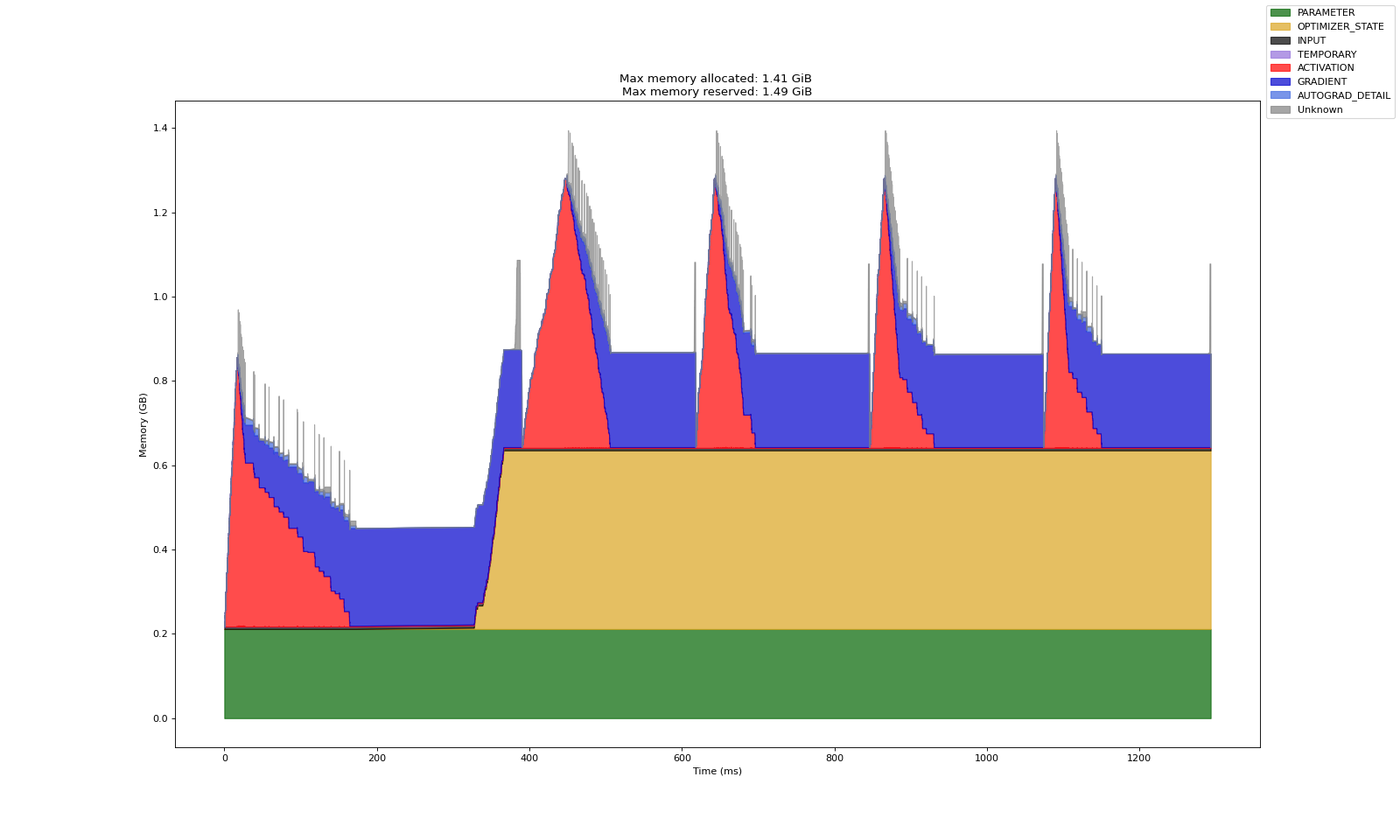
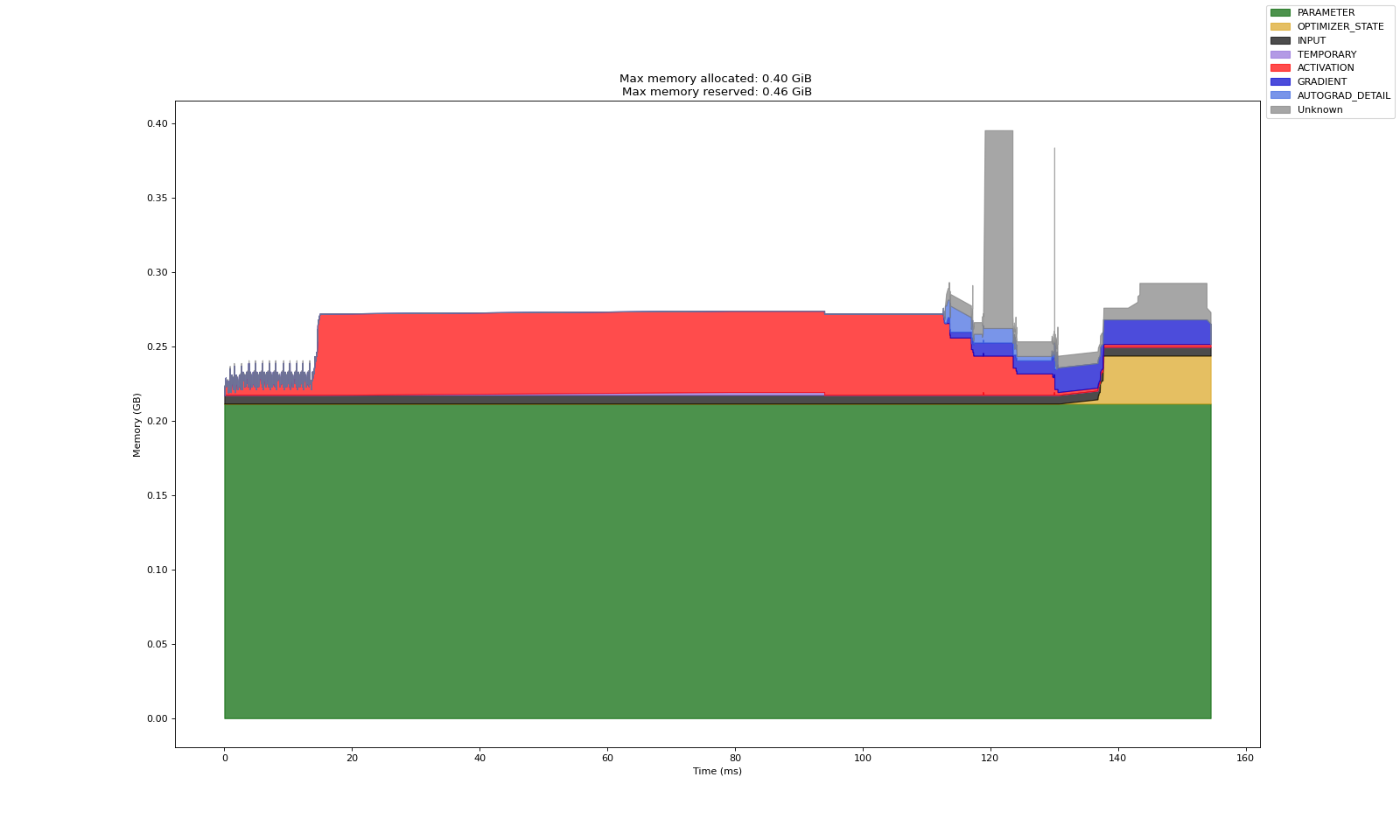
实验 A:全量调整模型
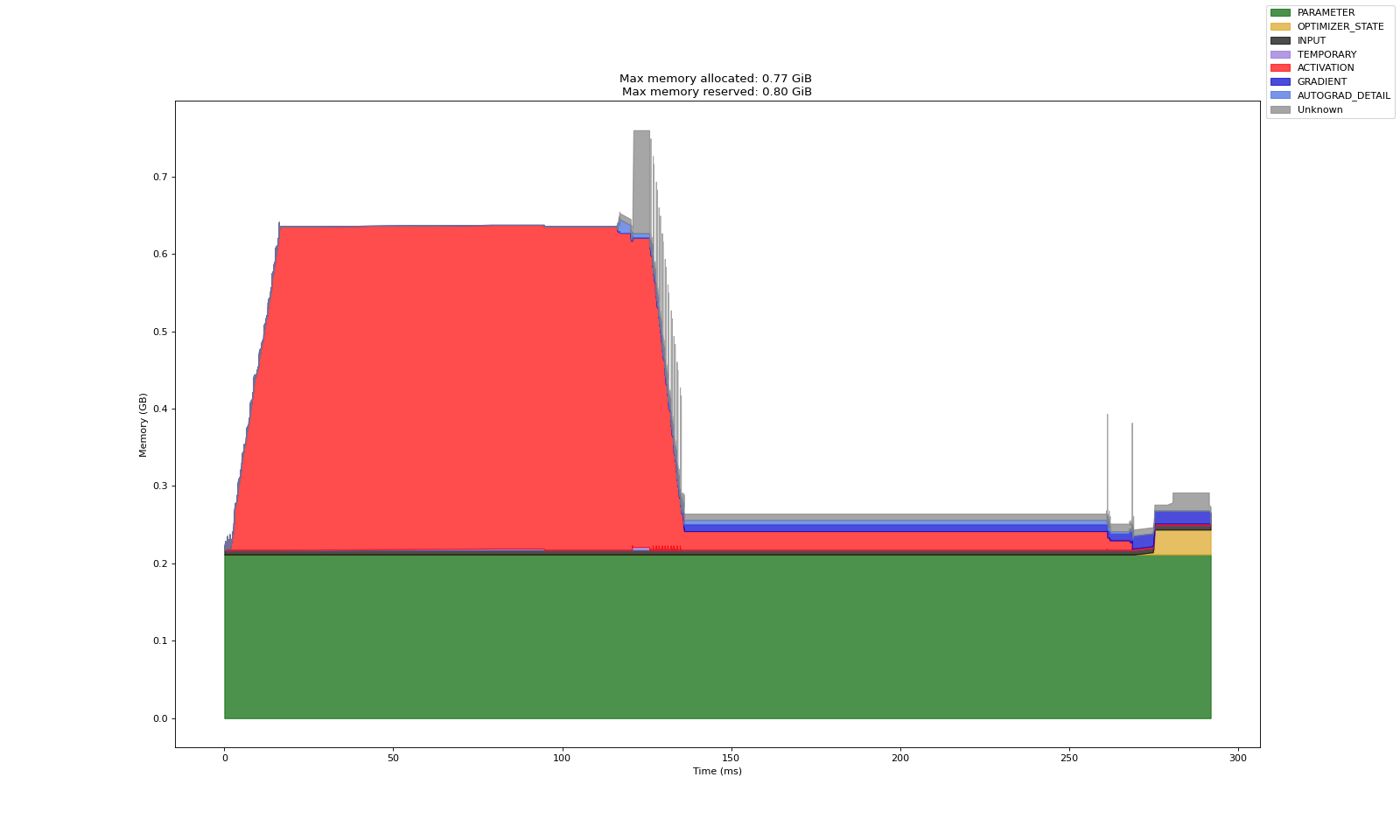
实验 B:冻结模型其他参数,仅调整第一层(前馈第一层)
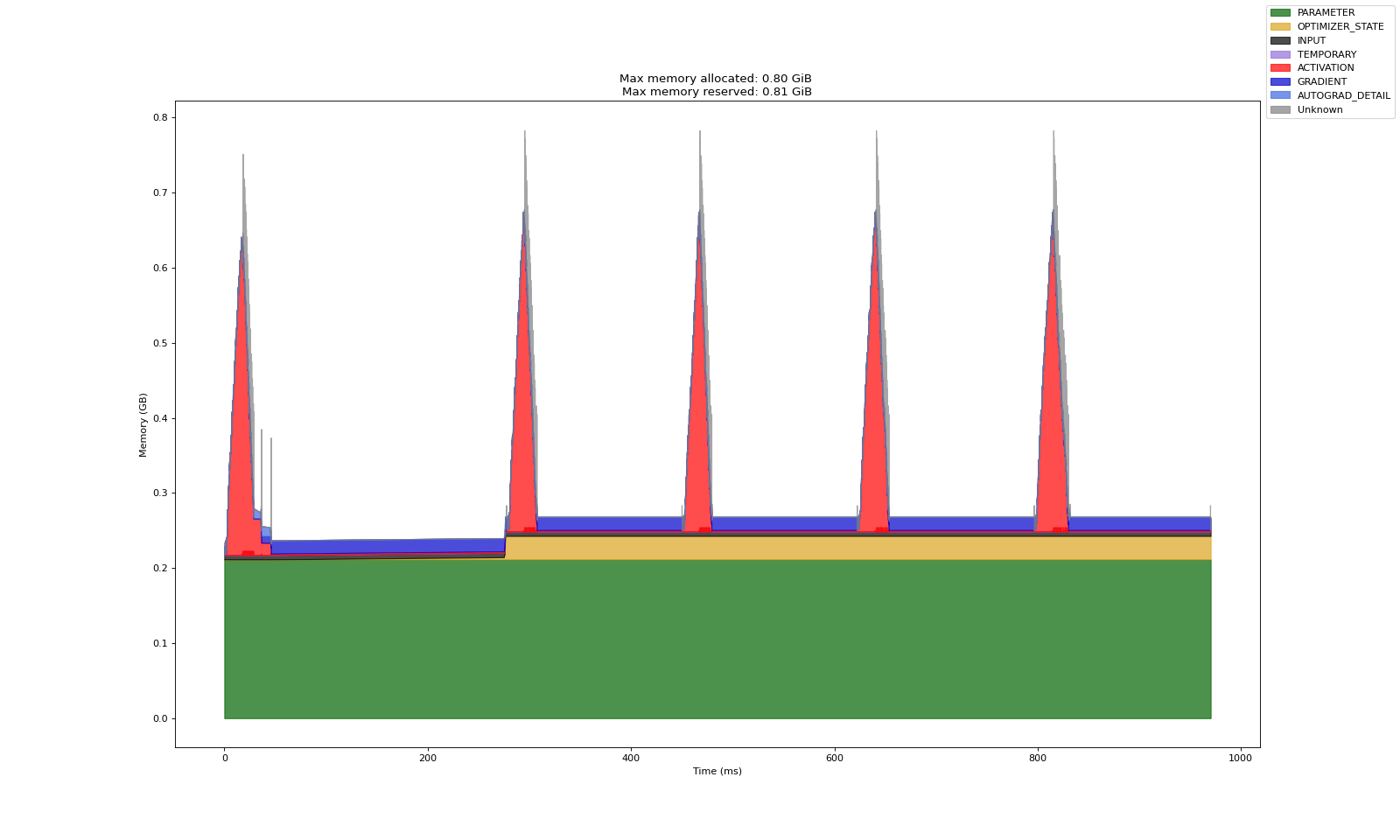
实验 C:冻结模型其他参数,仅调整最后一层(前馈最后一层)
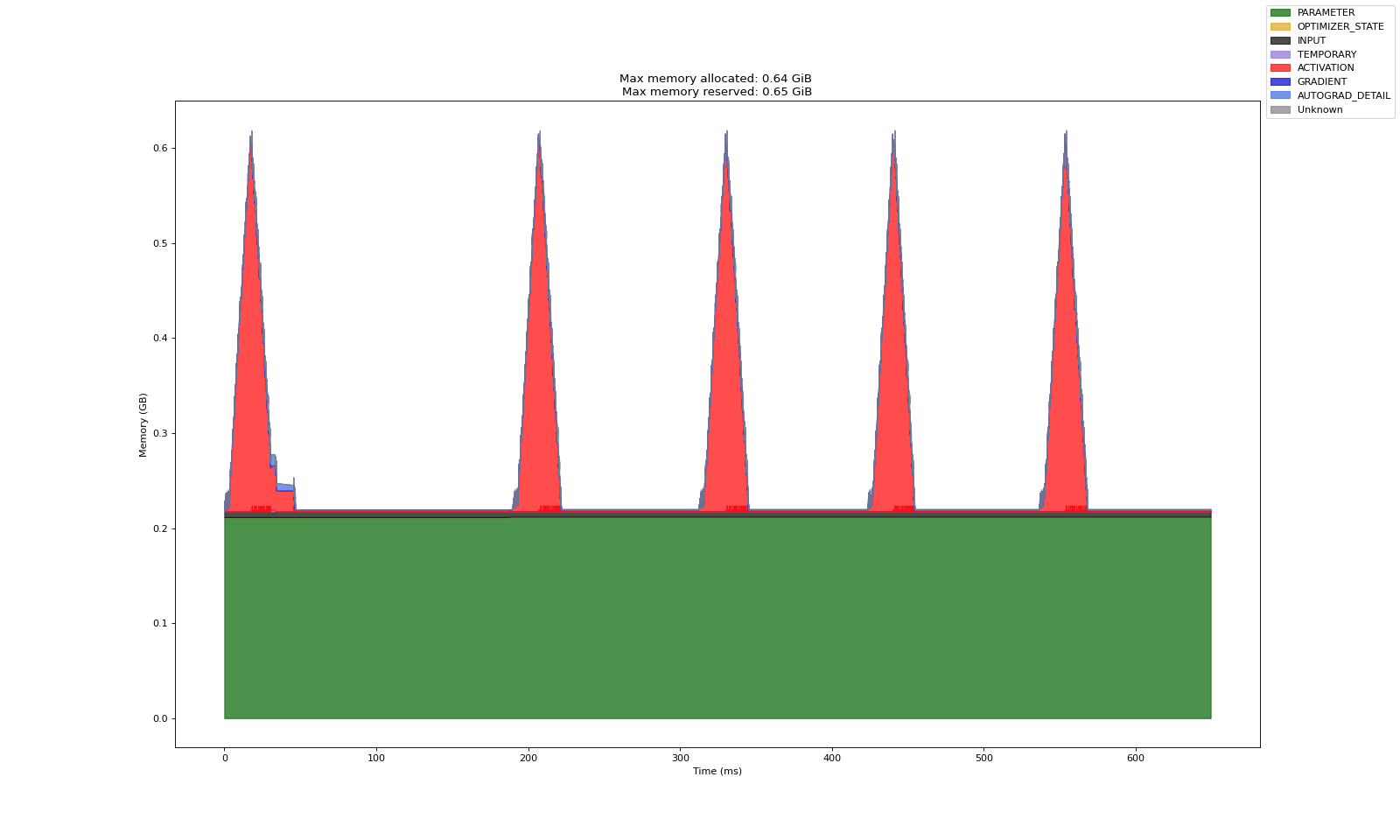
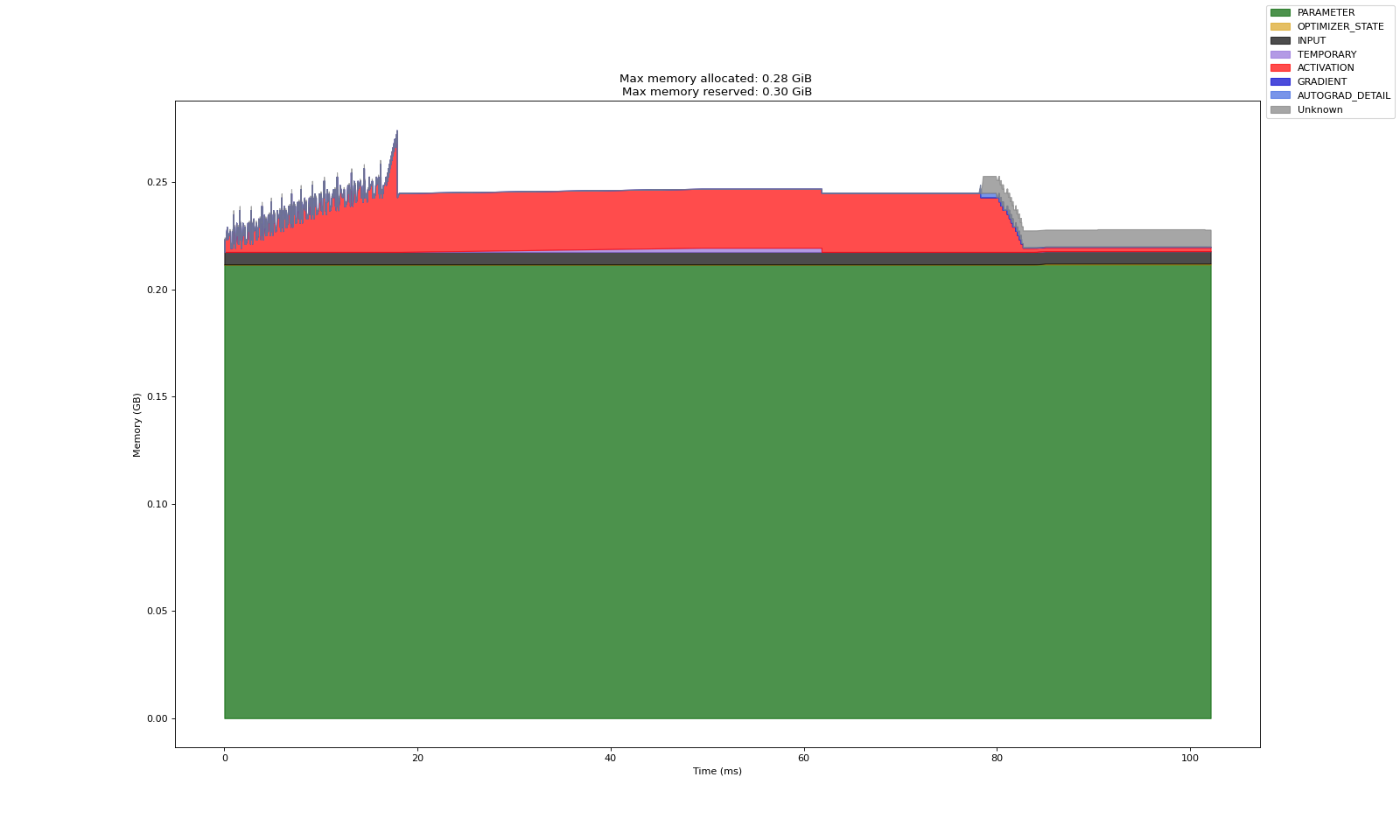
上述三个实验中,第一张图是 Warm up 产出的数据(预热数据,分析意义一般)
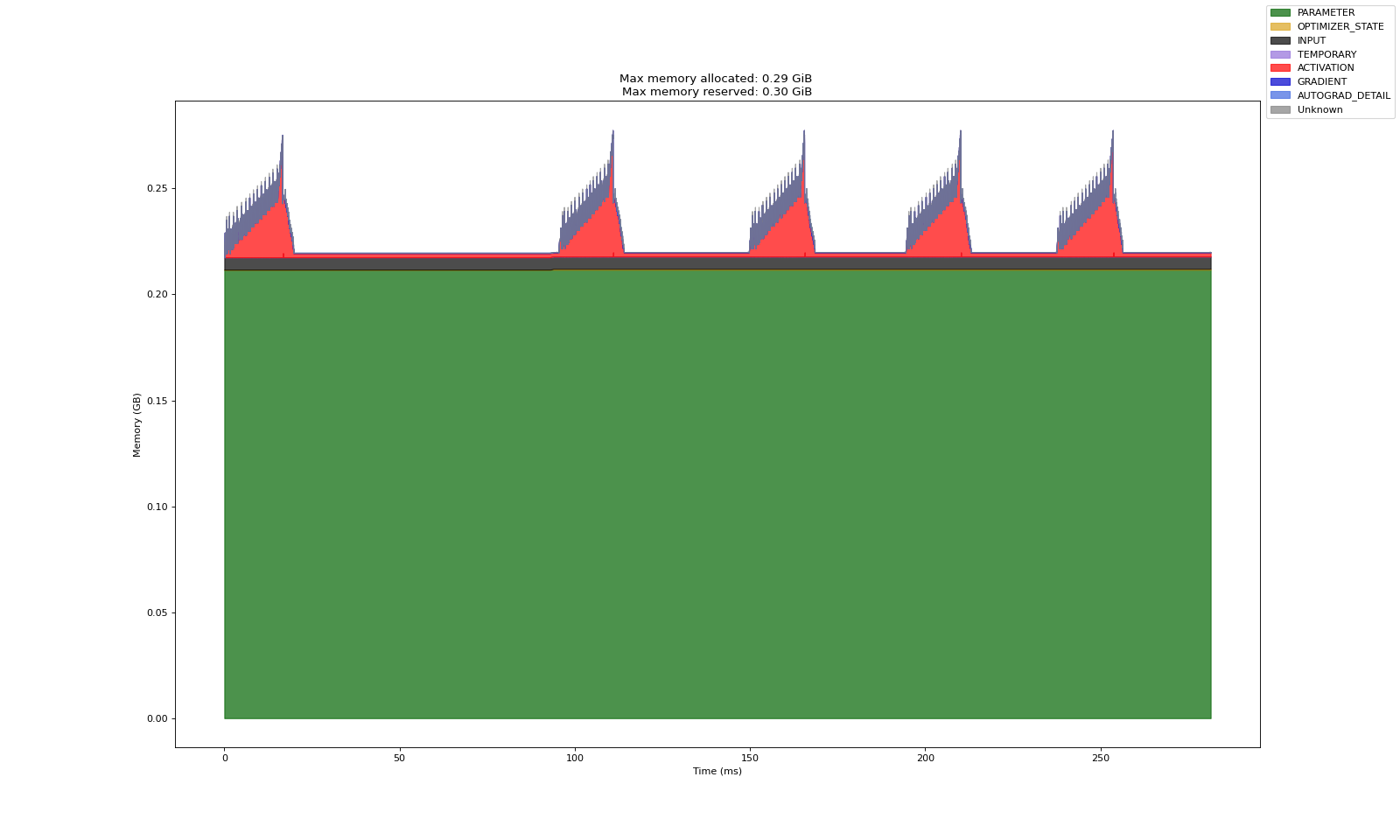
第二张图表示多轮训练中的显存开销记录数据
从实验共性看,基本可以论证以下事实:
Adam 造成的显存开销基本等于梯度的两倍,梯度开销基本等于模型训练参数的显存开销
激活显存在反向传播中会被逐渐释放,梯度显存仅存在于反向传播内,前馈过程中不会直接计算
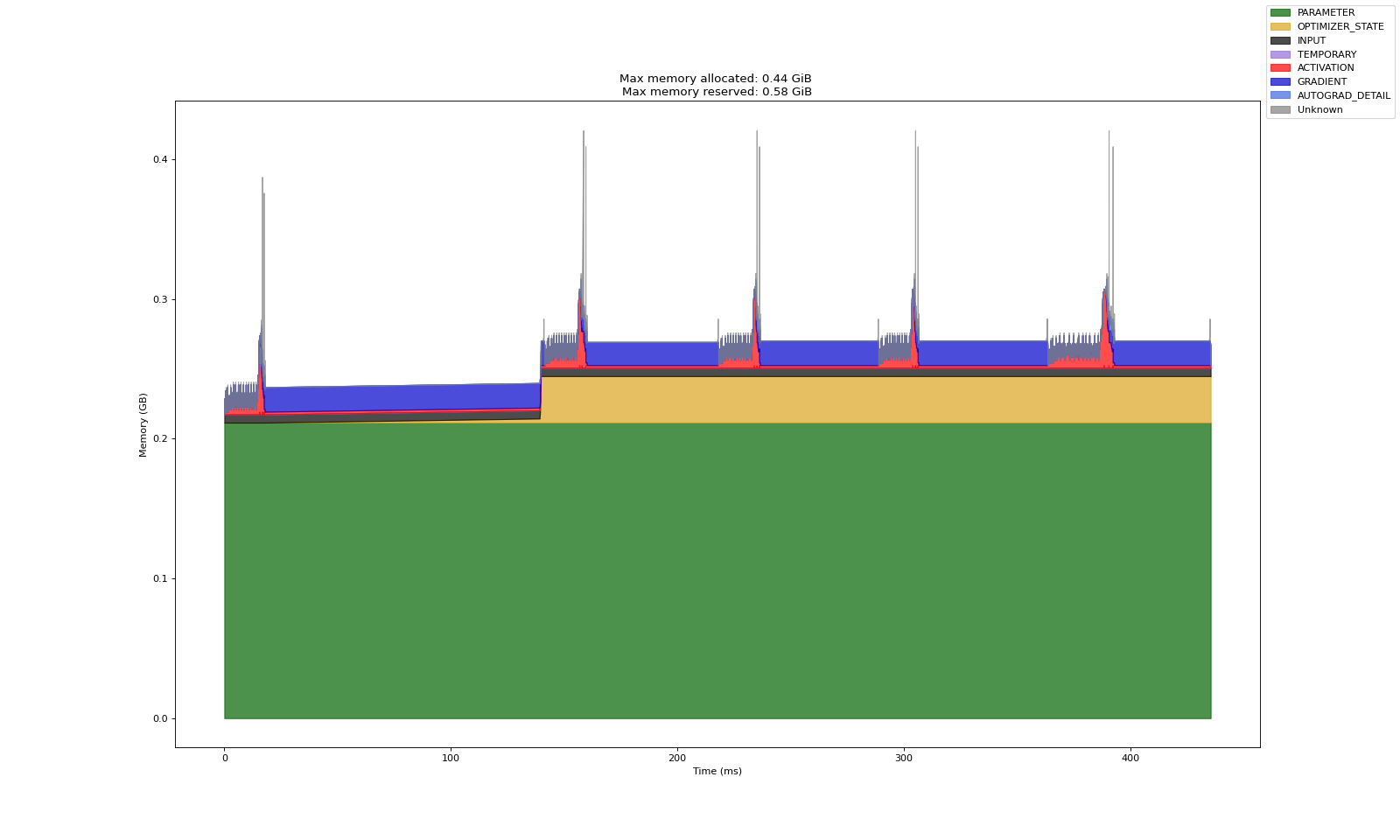
关于实验 A、B、C 对比可说明的结论:
即使训练参数量一致,参数在模型中所处的位置会显著影响显存的开销
其核心在于激活显存的保留与否
首层的梯度计算依赖于链式法则,必须通过其余层的激活显存来传递从而计算梯度
末层的梯度计算不依赖其余层,不需要通过其余层的激活显存来计算梯度
而某个参数的激活显存若在反向传播中不会用到,那么框架内会自动释放该激活显存
于是两者就产生了较大的显存差异
关于对比实验 A、B 可说明的结论:
理论上,调整第一层所涉及的参数应当是整个模型,因而激活值应当和全量调整时保持一致
而实际上,前馈过程中的激活显存能看到比较明显的下降
其具体原理暂时不得而知,但是确实能看到这样一个结果,可以先保留研究
关于速度相关的结论
其实从速度上面讲,也能看到明显的速度变化,逐个实验逐渐加速
理论上面的讲解还待进一步学习,同样保留研究
关于显存的可视化:(参考以下代码复现上述结果)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import torch from torch import nn from datetime import datetime from torch.autograd.profiler import record_function def trace_handler(prof: torch.profiler.profile): # 获取时间用于文件命名 timestamp = datetime.now().strftime('%Y_%m_%d_%H_%M_%S') file_name = f"visual_mem_{timestamp}" # 导出tracing格式的profiling prof.export_chrome_trace(f"{file_name}.json") # 导出mem消耗可视化数据 prof.export_memory_timeline(f"{file_name}.html", device="cuda:0") def train(num_iter=5, device="cuda:0"): model = nn.Transformer(d_model=512, nhead=2, num_encoder_layers=2, num_decoder_layers=12).to(device=device) x = torch.randn(size=(1, 1024, 512), device=device) tgt = torch.rand(size=(1, 1024, 512), device=device) model.train() for param in model.parameters(): param.requires_grad = False for param in model.decoder.layers[0].parameters(): param.requires_grad = True labels = torch.rand_like(model(x, tgt)) criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters()) with torch.profiler.profile( activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA], schedule=torch.profiler.schedule(wait=0, warmup=0, active=6, repeat=1), record_shapes=True, profile_memory=True, with_stack=True, on_trace_ready=trace_handler, ) as prof: for _ in range(num_iter): prof.step() with record_function("## forward ##"): y = model(x, tgt) with record_function("## backward ##"): loss = criterion(y, labels) loss.backward() print(loss.item()) with record_function("## optimizer ##"): optimizer.step() optimizer.zero_grad(set_to_none=True) if __name__ == "__main__": # warm-up: train(1) # run: train(5)
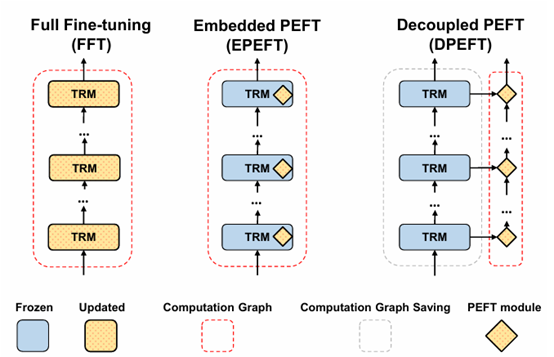
嵌入式 PEFT、解耦式 PEFT:
先前的实验结论同样可以套用到 PEFT 结构上:
全量式:
嵌入式:
解耦式:
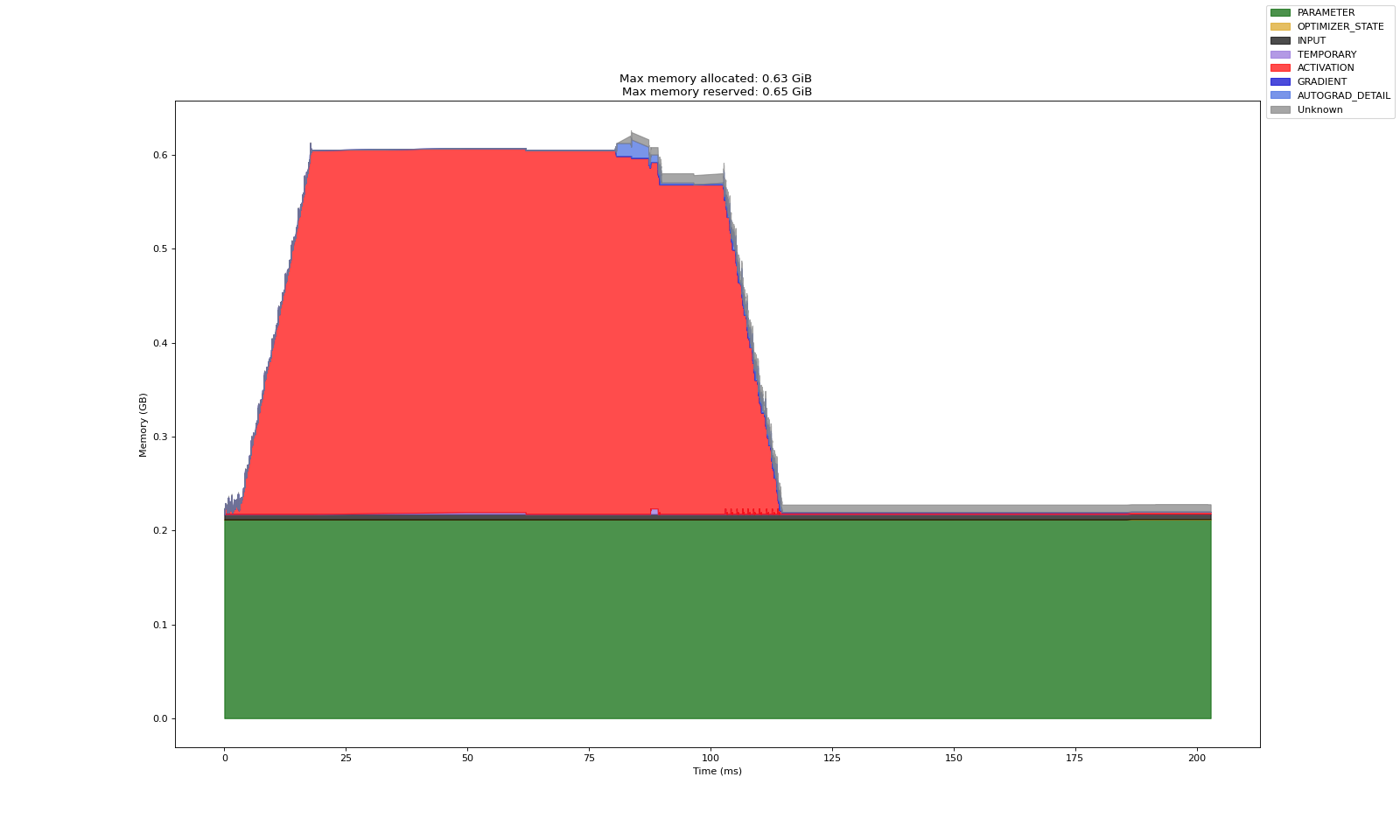
嵌入式 PEFT 由于会改变模型每层的输入输出,因而为计算其梯度,必须保存主干模型的激活显存
不过同先前实验中验证的一样,似乎不会全部保存,相比全量激活显存仍有一定程度下降
解耦式 PEFT 由于完全不变动模型主干每层的输入输出,因而主干模型的激活显存会自动被释放
相比嵌入式而言,其显存开销明显降低,计算速度上也有显著的提升
虽然计算速度上面依旧存在一定疑惑,有待未来进一步研究(总体看是减少计算量)
注:可以考虑缓存主干模型的方案,会进一步降低显存开销、提升训练速度
总结:
嵌入式,激活显存能产生一定下降,梯度能下降,优化器状态能下降
解耦式,激活显存能产生明显下降,梯度能下降,优化器状态能下降
相关代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 from datetime import datetime from torch.autograd.profiler import record_function import torch from torch import nn import math class MyTransformer(nn.Module): def __init__(self, d_model=512, nhead=2, num_encoder_layers=2, num_decoder_layers=12): super().__init__() self.d_model = d_model self.nhead = nhead self.num_encoder_layers = num_encoder_layers self.num_decoder_layers = num_decoder_layers # Encoder layers self.encoder_layers = nn.ModuleList([ nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead) for _ in range(num_encoder_layers) ]) self.encoder_norm = nn.LayerNorm(d_model) # Decoder layers + LoRA self.decoder_layers = nn.ModuleList([ LoRADecoderLayer(nn.TransformerDecoderLayer(d_model=d_model, nhead=nhead), d_model=d_model, rank=4, alpha=2) for _ in range(num_decoder_layers) ]) self.decoder_norm = nn.LayerNorm(d_model) def forward(self, src, tgt): # src: (batch, seq, d_model), tgt: (batch, seq, d_model) # Transformer expects (seq, batch, d_model) src = src.transpose(0, 1) tgt = tgt.transpose(0, 1) # Encoder forward memory = src for layer in self.encoder_layers: memory = layer(memory) memory = self.encoder_norm(memory) # Decoder forward output = tgt for layer in self.decoder_layers: output = layer(output, memory) output = self.decoder_norm(output) # Back to (batch, seq, d_model) return output.transpose(0, 1) class LoRA(nn.Module): def __init__(self, in_features, out_features, rank=4, alpha=1.0): super().__init__() self.rank = rank self.alpha = alpha self.W_down = nn.Linear(in_features, rank, bias=False) self.W_up = nn.Linear(rank, out_features, bias=False) nn.init.zeros_(self.W_up.weight) nn.init.kaiming_uniform_(self.W_down.weight, a=math.sqrt(5)) def forward(self, x): return self.alpha * self.W_up(self.W_down(x)) class LoRADecoderLayer(nn.Module): """ 将 LoRA 嵌入到 TransformerDecoderLayer """ def __init__(self, base_layer: nn.TransformerDecoderLayer, d_model, rank=4, alpha=1.0): super().__init__() self.base_layer = base_layer # LoRA 层输入输出维度同 d_model self.lora = LoRA(d_model, d_model, rank=rank, alpha=alpha) def forward(self, tgt, memory, tgt_mask=None, memory_mask=None, tgt_key_padding_mask=None, memory_key_padding_mask=None): # LoRA 输出 y1 = self.lora(tgt) # 原始 TransformerDecoderLayer 输出 y2 = self.base_layer(tgt, memory, tgt_mask=tgt_mask, memory_mask=memory_mask, tgt_key_padding_mask=tgt_key_padding_mask, memory_key_padding_mask=memory_key_padding_mask) # 相加作为本层输出 return y1 + y2 def trace_handler(prof: torch.profiler.profile): # 获取时间用于文件命名 timestamp = datetime.now().strftime('%Y_%m_%d_%H_%M_%S') file_name = f"visual_mem_{timestamp}" # 导出tracing格式的profiling prof.export_chrome_trace(f"{file_name}.json") # 导出mem消耗可视化数据 prof.export_memory_timeline(f"{file_name}.html", device="cuda:0") def train(num_iter=5, device="cuda:0"): model = MyTransformer(d_model=512, nhead=2, num_encoder_layers=2, num_decoder_layers=12).to(device=device) x = torch.randn(size=(1, 1024, 512), device=device) tgt = torch.rand(size=(1, 1024, 512), device=device) model.train() for param in model.parameters(): param.requires_grad = False for decoder_layer in model.decoder_layers: for param in decoder_layer.lora.parameters(): param.requires_grad = True labels = torch.rand_like(model(x, tgt)) criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters()) with torch.profiler.profile( activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA], schedule=torch.profiler.schedule(wait=0, warmup=0, active=6, repeat=1), record_shapes=True, profile_memory=True, with_stack=True, on_trace_ready=trace_handler, ) as prof: for _ in range(num_iter): prof.step() with record_function("## forward ##"): y = model(x, tgt) with record_function("## backward ##"): loss = criterion(y, labels) loss.backward() print(loss.item()) with record_function("## optimizer ##"): optimizer.step() optimizer.zero_grad(set_to_none=True) if __name__ == "__main__": # warm-up: train(1) # run: train(5)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 from datetime import datetime from torch.autograd.profiler import record_function import torch from torch import nn import math class LoRA(nn.Module): def __init__(self, in_features, out_features, rank=4, alpha=1.0): super().__init__() self.rank = rank self.alpha = alpha self.W_down = nn.Linear(in_features, rank, bias=False) self.W_up = nn.Linear(rank, out_features, bias=False) nn.init.zeros_(self.W_up.weight) nn.init.kaiming_uniform_(self.W_down.weight, a=math.sqrt(5)) def forward(self, x): return self.alpha * self.W_up(self.W_down(x)) class LoRATower(nn.Module): """ LoRA 塔,每层输入 = 当前 Decoder 层输出 + 上一层 LoRA 输出 """ def __init__(self, num_layers, d_model, rank=4, alpha=1.0): super().__init__() self.num_layers = num_layers self.lora_layers = nn.ModuleList([ LoRA(d_model, d_model, rank=rank, alpha=alpha) for _ in range(num_layers) ]) def forward(self, decoder_outputs): """ decoder_outputs: list of tensors from each decoder layer, shape (seq, batch, d_model) """ lora_out = torch.zeros_like(decoder_outputs[0]) for i, (layer, dec_out) in enumerate(zip(self.lora_layers, decoder_outputs)): lora_in = dec_out + lora_out lora_out = layer(lora_in) return lora_out class MyTransformerWithLoRATower(nn.Module): def __init__(self, d_model=512, nhead=2, num_encoder_layers=2, num_decoder_layers=12, lora_rank=4, lora_alpha=1.0): super().__init__() self.d_model = d_model self.nhead = nhead self.num_encoder_layers = num_encoder_layers self.num_decoder_layers = num_decoder_layers # 原 Transformer self.encoder_layers = nn.ModuleList([ nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead) for _ in range(num_encoder_layers) ]) self.encoder_norm = nn.LayerNorm(d_model) self.decoder_layers = nn.ModuleList([ nn.TransformerDecoderLayer(d_model=d_model, nhead=nhead) for _ in range(num_decoder_layers) ]) self.decoder_norm = nn.LayerNorm(d_model) # LoRA 塔 self.lora_tower = LoRATower(num_layers=num_decoder_layers, d_model=d_model, rank=lora_rank, alpha=lora_alpha) def forward(self, src, tgt): src = src.transpose(0, 1) tgt = tgt.transpose(0, 1) # Encoder memory = src for layer in self.encoder_layers: memory = layer(memory) memory = self.encoder_norm(memory) # Decoder forward output = tgt decoder_layer_outputs = [] for layer in self.decoder_layers: output = layer(output, memory) decoder_layer_outputs.append(output) output = self.decoder_norm(output) # LoRA 塔输出 lora_out = self.lora_tower(decoder_layer_outputs) # 最终输出 = 原 Transformer 输出 + LoRA 塔输出 return (output + lora_out).transpose(0, 1) def trace_handler(prof: torch.profiler.profile): # 获取时间用于文件命名 timestamp = datetime.now().strftime('%Y_%m_%d_%H_%M_%S') file_name = f"visual_mem_{timestamp}" # 导出tracing格式的profiling prof.export_chrome_trace(f"{file_name}.json") # 导出mem消耗可视化数据 prof.export_memory_timeline(f"{file_name}.html", device="cuda:0") def train(num_iter=5, device="cuda:0"): # model = MyTransformer(d_model=512, nhead=2, num_encoder_layers=2, num_decoder_layers=12).to(device=device) model = MyTransformerWithLoRATower(d_model=512, nhead=2, num_encoder_layers=2, num_decoder_layers=12, lora_rank=4, lora_alpha=1.0).to(device=device) x = torch.randn(size=(1, 1024, 512), device=device) tgt = torch.rand(size=(1, 1024, 512), device=device) model.train() for param in model.parameters(): param.requires_grad = False for param in model.lora_tower.parameters(): param.requires_grad = True labels = torch.rand_like(model(x, tgt)) criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters()) with torch.profiler.profile( activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA], schedule=torch.profiler.schedule(wait=0, warmup=0, active=6, repeat=1), record_shapes=True, profile_memory=True, with_stack=True, on_trace_ready=trace_handler, ) as prof: for _ in range(num_iter): prof.step() with record_function("## forward ##"): y = model(x, tgt) with record_function("## backward ##"): loss = criterion(y, labels) loss.backward() print(loss.item()) with record_function("## optimizer ##"): optimizer.step() optimizer.zero_grad(set_to_none=True) if __name__ == "__main__": # warm-up: train(1) # run: train(5)
开销时间相关实验:
实验 A:全量调整模型
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 from datetime import datetime from torch.autograd.profiler import record_function import torch from torch import nn import math class MyTransformer(nn.Module): def __init__(self, d_model=512, nhead=2, num_encoder_layers=2, num_decoder_layers=12): super().__init__() self.d_model = d_model self.nhead = nhead self.num_encoder_layers = num_encoder_layers self.num_decoder_layers = num_decoder_layers # Encoder layers self.encoder_layers = nn.ModuleList([ nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead) for _ in range(num_encoder_layers) ]) self.encoder_norm = nn.LayerNorm(d_model) # Decoder layers self.decoder_layers = nn.ModuleList([ nn.TransformerDecoderLayer(d_model=d_model, nhead=nhead) for _ in range(num_decoder_layers) ]) self.decoder_norm = nn.LayerNorm(d_model) def forward(self, src, tgt): # src: (batch, seq, d_model), tgt: (batch, seq, d_model) # Transformer expects (seq, batch, d_model) src = src.transpose(0, 1) tgt = tgt.transpose(0, 1) # Encoder forward memory = src for layer in self.encoder_layers: memory = layer(memory) memory = self.encoder_norm(memory) # Decoder forward output = tgt for layer in self.decoder_layers: output = layer(output, memory) output = self.decoder_norm(output) # Back to (batch, seq, d_model) return output.transpose(0, 1) class LoRA(nn.Module): """ 小型 LoRA 模块: 输入 -> W_down -> W_up -> 输出 """ def __init__(self, in_features, out_features, rank=4, alpha=1.0): """ in_features: 输入特征维度 out_features: 输出特征维度 rank: 低秩维度 r alpha: 缩放系数 """ super().__init__() self.rank = rank self.alpha = alpha # 下降层:将输入降到低秩空间 self.W_down = nn.Linear(in_features, rank, bias=False) # 提升层:将低秩表示升回输出维度 self.W_up = nn.Linear(rank, out_features, bias=False) # 初始化 LoRA 层 nn.init.zeros_(self.W_up.weight) # 提升层权重初始化为0 nn.init.kaiming_uniform_(self.W_down.weight, a=math.sqrt(5)) def forward(self, x): """ 输入 x: (..., in_features) 输出: (..., out_features) """ return self.alpha * self.W_up(self.W_down(x)) def trace_handler(prof: torch.profiler.profile): # 获取时间用于文件命名 timestamp = datetime.now().strftime('%Y_%m_%d_%H_%M_%S') file_name = f"visual_mem_{timestamp}" # 导出tracing格式的profiling prof.export_chrome_trace(f"{file_name}.json") # 导出mem消耗可视化数据 prof.export_memory_timeline(f"{file_name}.html", device="cuda:0") def train(num_iter=5, device="cuda:0"): model = MyTransformer(d_model=512, nhead=2, num_encoder_layers=2, num_decoder_layers=12).to(device=device) x = torch.randn(size=(1, 1024, 512), device=device) tgt = torch.rand(size=(1, 1024, 512), device=device) model.train() labels = torch.rand_like(model(x, tgt)) criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters()) with torch.profiler.profile( activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA], schedule=torch.profiler.schedule(wait=0, warmup=0, active=6, repeat=1), record_shapes=True, profile_memory=True, with_stack=True, on_trace_ready=trace_handler, ) as prof: for _ in range(num_iter): prof.step() with record_function("## forward ##"): y = model(x, tgt) with record_function("## backward ##"): loss = criterion(y, labels) loss.backward() print(loss.item()) with record_function("## optimizer ##"): optimizer.step() optimizer.zero_grad(set_to_none=True) with record_function("## end ##"): _ = _ + 1 if __name__ == "__main__": # warm-up: train(1) # run: train(5)
实验 B:嵌入式 PEFT 微调模型
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 from datetime import datetime from torch.autograd.profiler import record_function import torch from torch import nn import math class MyTransformer(nn.Module): def __init__(self, d_model=512, nhead=2, num_encoder_layers=2, num_decoder_layers=12): super().__init__() self.d_model = d_model self.nhead = nhead self.num_encoder_layers = num_encoder_layers self.num_decoder_layers = num_decoder_layers # Encoder layers self.encoder_layers = nn.ModuleList([ nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead) for _ in range(num_encoder_layers) ]) self.encoder_norm = nn.LayerNorm(d_model) # Decoder layers + LoRA self.decoder_layers = nn.ModuleList([ LoRADecoderLayer(nn.TransformerDecoderLayer(d_model=d_model, nhead=nhead), d_model=d_model, rank=4, alpha=2) for _ in range(num_decoder_layers) ]) self.decoder_norm = nn.LayerNorm(d_model) def forward(self, src, tgt): # src: (batch, seq, d_model), tgt: (batch, seq, d_model) # Transformer expects (seq, batch, d_model) src = src.transpose(0, 1) tgt = tgt.transpose(0, 1) # Encoder forward memory = src for layer in self.encoder_layers: memory = layer(memory) memory = self.encoder_norm(memory) # Decoder forward output = tgt for layer in self.decoder_layers: output = layer(output, memory) output = self.decoder_norm(output) # Back to (batch, seq, d_model) return output.transpose(0, 1) class LoRA(nn.Module): def __init__(self, in_features, out_features, rank=4, alpha=1.0): super().__init__() self.rank = rank self.alpha = alpha self.W_down = nn.Linear(in_features, rank, bias=False) self.W_up = nn.Linear(rank, out_features, bias=False) nn.init.zeros_(self.W_up.weight) nn.init.kaiming_uniform_(self.W_down.weight, a=math.sqrt(5)) def forward(self, x): return self.alpha * self.W_up(self.W_down(x)) class LoRADecoderLayer(nn.Module): """ 将 LoRA 嵌入到 TransformerDecoderLayer """ def __init__(self, base_layer: nn.TransformerDecoderLayer, d_model, rank=4, alpha=1.0): super().__init__() self.base_layer = base_layer # LoRA 层输入输出维度同 d_model self.lora = LoRA(d_model, d_model, rank=rank, alpha=alpha) def forward(self, tgt, memory, tgt_mask=None, memory_mask=None, tgt_key_padding_mask=None, memory_key_padding_mask=None): # LoRA 输出 y1 = self.lora(tgt) # 原始 TransformerDecoderLayer 输出 y2 = self.base_layer(tgt, memory, tgt_mask=tgt_mask, memory_mask=memory_mask, tgt_key_padding_mask=tgt_key_padding_mask, memory_key_padding_mask=memory_key_padding_mask) # 相加作为本层输出 return y1 + y2 def trace_handler(prof: torch.profiler.profile): # 获取时间用于文件命名 timestamp = datetime.now().strftime('%Y_%m_%d_%H_%M_%S') file_name = f"visual_mem_{timestamp}" # 导出tracing格式的profiling prof.export_chrome_trace(f"{file_name}.json") # 导出mem消耗可视化数据 prof.export_memory_timeline(f"{file_name}.html", device="cuda:0") def train(num_iter=5, device="cuda:0"): model = MyTransformer(d_model=512, nhead=2, num_encoder_layers=2, num_decoder_layers=12).to(device=device) x = torch.randn(size=(1, 1024, 512), device=device) tgt = torch.rand(size=(1, 1024, 512), device=device) model.train() for param in model.parameters(): param.requires_grad = False for decoder_layer in model.decoder_layers: for param in decoder_layer.lora.parameters(): param.requires_grad = True labels = torch.rand_like(model(x, tgt)) criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters()) with torch.profiler.profile( activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA], schedule=torch.profiler.schedule(wait=0, warmup=0, active=6, repeat=1), record_shapes=True, profile_memory=True, with_stack=True, on_trace_ready=trace_handler, ) as prof: for _ in range(num_iter): prof.step() with record_function("## forward ##"): y = model(x, tgt) with record_function("## backward ##"): loss = criterion(y, labels) loss.backward() print(loss.item()) with record_function("## optimizer ##"): optimizer.step() optimizer.zero_grad(set_to_none=True) with record_function("## end ##"): _ = _ + 2 if __name__ == "__main__": # warm-up: train(1) # run: train(5)
实验 C:解耦式 PEFT 微调模型
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 from datetime import datetime from torch.autograd.profiler import record_function import torch from torch import nn import math class LoRA(nn.Module): def __init__(self, in_features, out_features, rank=4, alpha=1.0): super().__init__() self.rank = rank self.alpha = alpha self.W_down = nn.Linear(in_features, rank, bias=False) self.W_up = nn.Linear(rank, out_features, bias=False) nn.init.zeros_(self.W_up.weight) nn.init.kaiming_uniform_(self.W_down.weight, a=math.sqrt(5)) def forward(self, x): return self.alpha * self.W_up(self.W_down(x)) class LoRATower(nn.Module): """ LoRA 塔,每层输入 = 当前 Decoder 层输出 + 上一层 LoRA 输出 """ def __init__(self, num_layers, d_model, rank=4, alpha=1.0): super().__init__() self.num_layers = num_layers self.lora_layers = nn.ModuleList([ LoRA(d_model, d_model, rank=rank, alpha=alpha) for _ in range(num_layers) ]) def forward(self, decoder_outputs): """ decoder_outputs: list of tensors from each decoder layer, shape (seq, batch, d_model) """ lora_out = torch.zeros_like(decoder_outputs[0]) for i, (layer, dec_out) in enumerate(zip(self.lora_layers, decoder_outputs)): lora_in = dec_out + lora_out lora_out = layer(lora_in) return lora_out class MyTransformerWithLoRATower(nn.Module): def __init__(self, d_model=512, nhead=2, num_encoder_layers=2, num_decoder_layers=12, lora_rank=4, lora_alpha=1.0): super().__init__() self.d_model = d_model self.nhead = nhead self.num_encoder_layers = num_encoder_layers self.num_decoder_layers = num_decoder_layers # 原 Transformer self.encoder_layers = nn.ModuleList([ nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead) for _ in range(num_encoder_layers) ]) self.encoder_norm = nn.LayerNorm(d_model) self.decoder_layers = nn.ModuleList([ nn.TransformerDecoderLayer(d_model=d_model, nhead=nhead) for _ in range(num_decoder_layers) ]) self.decoder_norm = nn.LayerNorm(d_model) # LoRA 塔 self.lora_tower = LoRATower(num_layers=num_decoder_layers, d_model=d_model, rank=lora_rank, alpha=lora_alpha) def forward(self, src, tgt): src = src.transpose(0, 1) tgt = tgt.transpose(0, 1) # Encoder memory = src for layer in self.encoder_layers: memory = layer(memory) memory = self.encoder_norm(memory) # Decoder forward output = tgt decoder_layer_outputs = [] for layer in self.decoder_layers: output = layer(output, memory) decoder_layer_outputs.append(output) output = self.decoder_norm(output) # LoRA 塔输出 lora_out = self.lora_tower(decoder_layer_outputs) # 最终输出 = 原 Transformer 输出 + LoRA 塔输出 return (output + lora_out).transpose(0, 1) def trace_handler(prof: torch.profiler.profile): # 获取时间用于文件命名 timestamp = datetime.now().strftime('%Y_%m_%d_%H_%M_%S') file_name = f"visual_mem_{timestamp}" # 导出tracing格式的profiling prof.export_chrome_trace(f"{file_name}.json") # 导出mem消耗可视化数据 prof.export_memory_timeline(f"{file_name}.html", device="cuda:0") def train(num_iter=5, device="cuda:0"): # model = MyTransformer(d_model=512, nhead=2, num_encoder_layers=2, num_decoder_layers=12).to(device=device) model = MyTransformerWithLoRATower(d_model=512, nhead=2, num_encoder_layers=2, num_decoder_layers=12, lora_rank=4, lora_alpha=1.0).to(device=device) x = torch.randn(size=(1, 1024, 512), device=device) tgt = torch.rand(size=(1, 1024, 512), device=device) model.train() for param in model.parameters(): param.requires_grad = False for param in model.lora_tower.parameters(): param.requires_grad = True labels = torch.rand_like(model(x, tgt)) criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters()) with torch.profiler.profile( activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA], schedule=torch.profiler.schedule(wait=0, warmup=0, active=6, repeat=1), record_shapes=True, profile_memory=True, with_stack=True, on_trace_ready=trace_handler, ) as prof: for _ in range(num_iter): prof.step() with record_function("## forward ##"): y = model(x, tgt) with record_function("## backward ##"): loss = criterion(y, labels) loss.backward() print(loss.item()) with record_function("## optimizer ##"): optimizer.step() optimizer.zero_grad(set_to_none=True) with record_function("## end ##"): _ = _ + 2 if __name__ == "__main__": # warm-up: train(1) # run: train(5)
显示代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import json import sys PHASE_NAMES = ["## forward ##", "## backward ##", "## optimizer ##", "## end ##"] def extract_phase_marked(json_path): with open(json_path, 'r', encoding='utf-8') as f: data = json.load(f) events = data.get("traceEvents", data) phase_starts = {name: [] for name in PHASE_NAMES} for e in events: if e.get("ph") != "X": continue if e.get("name") in PHASE_NAMES: phase_starts[e["name"]].append(e["ts"]) return {k: v for k, v in phase_starts.items() if v} def main(): if len(sys.argv) < 2: print("Usage: python show_times.py trace.json") sys.exit(1) json_path = sys.argv[1] phases = extract_phase_marked(json_path) if not phases: print("No forward/backward/optimizer/end events found.") return num_iters = min(len(phases[name]) for name in PHASE_NAMES) print(f"Per-iteration phase times (ms):") for i in range(num_iters): f_ts = phases["## forward ##"][i] b_ts = phases["## backward ##"][i] o_ts = phases["## optimizer ##"][i] e_ts = phases["## end ##"][i] forward_ms = (b_ts - f_ts) / 1000.0 backward_ms = (o_ts - b_ts) / 1000.0 optimizer_ms = (e_ts - o_ts) / 1000.0 print(f"Iter {i+1:>2}: Forward: {forward_ms:7.3f} ms | " f"Backward: {backward_ms:7.3f} ms | " f"Optimizer: {optimizer_ms:7.3f} ms") if __name__ == "__main__": main()
实验效果:
实验架构图与理论分析
从理论上讲,全量调整、嵌入式 PEFT、解耦式 PEFT 的时间复杂度应当如下:
其中,FP/fp 代表主干/PEFT 前馈,BP/bp 代表主干/PEFT反馈,WU/wu 代表主干/PEFT 参数更新
O(FP+BP+WU),其理论上需要经过如此时间
O(FP+fp+BP+bp+wu),理论上 fp 和 FP / bp 和 BP 会有重叠,不会造成完全的线性相加
O(FP+fp+bp+wu),其中 fp 和 FP 理论上会有重叠,不会造成完全线性相加
全量调整:
嵌入式:
解耦式:
分析:
上述理论分析中,嵌入式的反向传播部分、嵌入/解耦式的参数更新部分实际效果同理论存在差异
反向传播是整个模型训练过程中开销最大的部分,这是一个事实//绝大多数情况下的事实
即使是嵌入式微调,依旧能够加速反向传播的速度 // 来源于各种各样的开销降低
前馈时间基本保持稳定,但理论上应该会因为 PEFT 组件的影响略微增长,小规模也可能产生下降
参数更新时间基本同参数量成正比,但嵌入/解耦或许会对其产生一定影响,解耦往往能更快
总结:( PEFT 总能造成显存下降和训练加速,各种层面和因素上)
嵌入式,前馈上基本不能加速甚至可能造成减速,反向能加速,更新参数能加速
解耦式,前馈没有产生明显减速可能造成加速,反向能明显加速,更新参数似乎能进一步加速