DataLoaderX(prefetcher_generator、BackgroundGenerator):
该方案的使用需要额外下载库:
1
| pip install prefetcher_generator
|
具体使用方法(案例):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| import numpy as np
import time
from prefetch_generator import BackgroundGenerator, background
# 模拟耗时 batch generator
def iterate_minibatches(n_batches=10, batch_size=10):
for _ in range(n_batches):
time.sleep(0.1) # 模拟数据生成耗时
X = np.random.randn(batch_size, 20)
y = np.random.randint(0, 2, batch_size)
yield X, y
# ---------------- 普通 generator ----------------
t0 = time.time()
for X, y in iterate_minibatches(10):
time.sleep(0.1) # 模拟训练
print('!', end=' ')
print('\n普通 generator耗时:', time.time()-t0)
# ---------------- BackgroundGenerator ----------------
t1 = time.time()
for X, y in BackgroundGenerator(iterate_minibatches(10), max_prefetch=3):
time.sleep(0.1) # 模拟训练
print('!', end=' ')
print('\nBackgroundGenerator耗时:', time.time()-t1)
# ---------------- @background 装饰器 ----------------
@background(max_prefetch=3)
def bg_iterate_minibatches(n_batches=10, batch_size=10):
for _ in range(n_batches):
time.sleep(0.1) # 模拟数据生成耗时
X = np.random.randn(batch_size, 20)
y = np.random.randint(0, 2, batch_size)
yield X, y
t2 = time.time()
for X, y in bg_iterate_minibatches(10):
time.sleep(0.1) # 模拟训练
print('!', end=' ')
print('\n@background耗时:', time.time()-t2)
|
同时,也可以用于 DataLoader 的包裹:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| import torch
from torch.utils.data import Dataset, DataLoader
from prefetch_generator import BackgroundGenerator
import time
import numpy as np
# ---------------- 简单 Dataset ----------------
class MyDataset(Dataset):
def __init__(self, size=20):
self.data = list(range(size))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
time.sleep(0.05) # 模拟数据读取或 CPU transform
return torch.tensor(self.data[idx])
# ---------------- DataLoaderX ----------------
class DataLoaderX(DataLoader):
"""
扩展 DataLoader,后台线程异步预取 batch
"""
def __iter__(self):
return BackgroundGenerator(super().__iter__(), max_prefetch=2)
# ---------------- 测试普通 DataLoader ----------------
dataset = MyDataset(20)
loader = DataLoader(dataset, batch_size=4, num_workers=2)
t0 = time.time()
for batch in loader:
time.sleep(0.1) # 模拟训练
print(batch, end=' ')
print('\n普通 DataLoader耗时:', time.time()-t0)
# ---------------- 测试 DataLoaderX ----------------
prefetch_loader = DataLoaderX(dataset, batch_size=4, num_workers=2)
t1 = time.time()
for batch in prefetch_loader:
time.sleep(0.1) # 模拟训练
print(batch, end=' ')
print('\nDataLoaderX耗时:', time.time()-t1)
|
下面即为改进后的运行流程图:
1
2
3
4
5
6
| 普通 generator:
[生成 batch0][训练 batch0][生成 batch1][训练 batch1]...
BackgroundGenerator:
后台线程: [生成 batch0] [生成 batch1] [生成 batch2] ...
主线程: [训练 batch0] [训练 batch1] [训练 batch2] ...
|
实际上将生成器、训练流程一分为二,异步进行
理论上,能够将原先数据加载后训练的流程变为边加载数据边训练的流程,大幅度提高效率
场景上,理论上最适合取数据时间较短但训练较慢的场景,可以达到完全异步效果
针对取数据时间较长、训练较快场景,同样可以降低启动开销、同步开销,令数据进程一直忙碌
可以认为是比较有效的策略,这个策略同样适用于 DataLoader
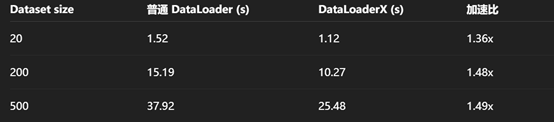
补注:
1.上述两个代码均可以运行,可以基于此结果进一步实验效果(验证上述理论)
其官方代码演示案例:
https://github.com/justheuristic/prefetch_generator/blob/master/example.ipynb
2.同时,可以针对数据集数量、预处理时间、主训练时间进行消融,从而得到最佳实践
