Pinned Memory
理论上其通过将数据放在锁页内存,且通过异步传输可以加速数据从内存到显存的传递速率
其案例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| import os
import time
import numpy as np
import pandas as pd
import torch
from torch.utils.data import Dataset, DataLoader
# ===== 自动生成 CSV 文件 =====
csv_path = "/data/ch/data.csv"
if not os.path.exists(csv_path):
N = 1000000 # 行数,可以调大
M = 21 # 列数,最后一列作为 label
df = pd.DataFrame(np.random.randn(N, M))
df.to_csv(csv_path, index=False)
print(f"已生成测试文件 {csv_path}")
# ===== 自定义 Dataset =====
class CSVDataset(Dataset):
def __init__(self, csv_path):
self.data = pd.read_csv(csv_path)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
row = self.data.iloc[idx]
x = torch.tensor(row.iloc[:-1].values, dtype=torch.float32)
y = torch.tensor(row.iloc[-1], dtype=torch.float32) # ✅ 改这里
return x, y
# ===== 测试函数 =====
def run_dataloader(csv_path, pin_memory=False, non_blocking=False):
dataset = CSVDataset(csv_path)
dataloader = DataLoader(
dataset,
batch_size=32768,
shuffle=True,
num_workers=2,
pin_memory=pin_memory # 锁页内存,固定放在某个页面,可加速数据拷贝
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
start = time.time()
for data, target in dataloader:
# 关键:用 non_blocking=True
data = data.to(device, non_blocking=non_blocking) # 异步传输
target = target.to(device, non_blocking=non_blocking) # 异步传输
# 模拟训练计算
_ = data * 2.0 + 1.0
end = time.time()
print(f"pin_memory={pin_memory}, time={end-start:.4f} s")
if __name__ == "__main__":
run_dataloader(csv_path, pin_memory=False, non_blocking = False)
run_dataloader(csv_path, pin_memory=True, non_blocking = True)
|
其最终的测试结果如下:(逐渐将 Batch Size 调大后的结果)
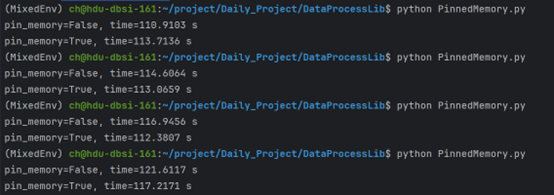
基本可以看到,Batch 较小的情况下,锁页、异步拷贝很难展现出效果
当 Batch 逐渐增大后,即可逐渐展现出效果,说明这个属性更适用于较大规模的数据拷贝、传输
当数据量较小时,由于锁页和异步拷贝本身会带来开销,反而会令加速效果不明显
CUDA Stream 结合:
