多进程并行(这里仅讨论单文件式数据文件)
目前已知信息:多进程情况时,getitem、collate 均在每个子进程的包裹下,均可实现并行
现有思路、方法(针对 CVS 等数据文件,非图像文件):
A:数据读取后放在内存,getitem 内放置数据预处理、collate 内放置数据预处理
理论上数据若能够被放入内存,那么这是最高效的方案
B:数据在 getitem 中按需读取,getitem 内放置数据预处理、collate 内放置数据预处理
理论上会产生大量 I/O 开销,即使能靠多进程并行读取加速,也无法贴近内存读取速度
C:数据按需预调用维护 chunk 放在内存,getitem 内放置数据预处理、collate 内放置数据预处理
理论上是最为高效的方案,能够在内存有限的情况下达到内存读取的效果,但实现略复杂
补注:
A 方案的缺陷在于需要占据大量内存,且一开始的读取也需要占用时间
B 方案缺陷在于会造成大量 I/O 开销
C 方案的实现上面较为复杂,首先需要实现 chunk 思路,然后还需要实现异步读取思路
目前有待进一步实验的内容:
1.内存读取的初始读取速率、I/O 速率,以及是否需要/可依靠多进程读取加速,读取速率影响因素
实验环境:Linux 云服务器环境,数据约 1.2 G
首先阐明事实,SSD/磁盘 读取 1.2 G 大小的 csv 文件,不可能耗费半分钟甚至更久
通过实验也可以佐证这一点:
Pandas 读取:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| import torch
from torch.utils.data import Dataset, DataLoader
import pandas as pd # pandas 读取
import time
# 自定义 Dataset
class CSVRowDataset(Dataset):
def __init__(self, csv_file):
# 用 pandas 读取 CSV
self.data = pd.read_csv(csv_file)
# 转为 Python list(保持一致)
self.values = self.data["value"].tolist()
def __len__(self):
return len(self.values)
def __getitem__(self, idx):
# 获取单行数据
value = self.values[idx]
return value
t0 = time.time()
# 创建 Dataset 实例
dataset = CSVRowDataset(r"/root/autodl-tmp/project3/data.csv")
# 创建 DataLoader
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
t1 = time.time()
print(f"初始化耗时: {t1 - t0:.2f}s")
|
Polars 读取:

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| import torch
from torch.utils.data import Dataset, DataLoader
import polars as pl # 用 Polars 替代 pandas
import time
# 自定义 Dataset
class CSVRowDataset(Dataset):
def __init__(self, csv_file):
# 用 Polars 读取 CSV(自动多线程)
self.data = pl.read_csv(csv_file, has_header=True)
# 转为 Python list(或直接用 Polars 列)
self.values = self.data["value"].to_list()
def __len__(self):
return len(self.values)
def __getitem__(self, idx):
# 获取单行数据
value = self.values[idx]
# 这里只演示字符串乘0,不转tensor
return value
t0 = time.time()
# 创建 Dataset 实例
dataset = CSVRowDataset(r"/root/autodl-tmp/project3/data.csv")
# 创建 DataLoader
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
t1 = time.time()
print(f"初始化耗时: {t1 - t0:.2f}s")
|

上述实验可以明确说明 I/O 不是数据读入内存的瓶颈,CPU 对数据读入后的解码、结构化才是
因而,自然可以依靠多进程读取加速(并行解码、结构化)
例如 Polars 就是一个多线程读取加速的方法,可以大幅度加速读入内存的速度(其他还有很多)
因而读取上多考虑处理器的问题,一般情况下不需要考虑 I/O 瓶颈
注:其余的读取加速策略可以自行搜索和学习(转化为二进制文件、流式读写、Rust)
2.内存读取、按需读取的总时间开销研究(不同设备、数据集大小、不同进程模式)及影响因素研究
3.内存读取、按需读取的内存开销研究(不同设备、数据集大小)及影响因素研究
4.按需读取的加速效果(主要研究加速在 I/O 还是数据预处理)及影响因素研究
5.I/O 开销的研究(读取时间、调用时间),以明确 I/O 开销的核心
从历史实验经验基本可以判断调用时间才是开销的核心,因为 SSD 带宽很少跑满
6.getitem、collate 内放置数据预处理策略的方案(不同设备、数据集大小、预处理策略等)
主要明确何时应当放在 getitem,何时放在 collate
7.chunk 的具体实现及速率研究(理论上速率应超过或者同内存读取持平)
实验环境:Linux 云服务器,1.2G csv 文本数据
下列为实验代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import pandas as pd
# 文件路径
csv_file = "/root/autodl-tmp/project3/data.csv"
offset_file = "/root/autodl-tmp/project3/data.offsets"
# 生成数据
num_rows = 100_000_000
data = (f"Row {i}" for i in range(1, num_rows + 1))
# 写 CSV + 记录偏移量
with open(csv_file, "w") as f_csv, open(offset_file, "w") as f_offset:
header = "value\n"
f_csv.write(header)
f_offset.write("0\n") # header 偏移量为0
offset = len(header.encode("utf-8")) # header长度(字节)
for row in data:
line = f"{row}\n"
f_csv.write(line)
f_offset.write(f"{offset}\n")
offset += len(line.encode("utf-8"))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| import numpy as np
from torch.utils.data import Dataset, DataLoader
import mmap
import time
import polars as pl
class FastCSVBatchDataset(Dataset):
def __init__(self, csv_file, offset_file, batch_size=256):
self.csv_file = csv_file
self.batch_size = batch_size
# ✅ 用 Polars 读取偏移文件(多线程)
self.offsets = pl.read_csv(offset_file, has_header=False).to_series().to_numpy()
self.length = len(self.offsets) - 1 # 减去 header
self.num_batches = (self.length + batch_size - 1) // batch_size
# ✅ 打开文件并建立内存映射(一次完成)
self._f = open(self.csv_file, "rb")
self.mm = mmap.mmap(self._f.fileno(), 0, access=mmap.ACCESS_READ)
def __len__(self):
return self.num_batches
def __getitem__(self, batch_idx):
start_row = batch_idx * self.batch_size
end_row = min(start_row + self.batch_size, self.length)
start_offset = self.offsets[start_row + 1] # +1 跳过 header
if end_row == self.length:
end_offset = len(self.mm)
else:
end_offset = self.offsets[end_row + 1]
# ✅ mmap 支持切片读取,无需 seek/read
data = self.mm[start_offset:end_offset].decode("utf-8")
# 保留 decode + splitlines 行为
return data.splitlines()
def __del__(self):
try:
if hasattr(self, "mm"):
self.mm.close()
if hasattr(self, "_f"):
self._f.close()
except Exception:
pass
# ===== 测试 =====
if __name__ == "__main__":
dataset = FastCSVBatchDataset(
"/data/ch/datax.csv",
"/data/ch/datax.offsets",
batch_size=256
)
dataloader = DataLoader(dataset, batch_size=None, shuffle=True, num_workers=8, persistent_workers=True)
num = 1
t0 = time.time()
for batch in dataloader:
if num % 10000 == 0:
print((time.time() - t0) / num)
num += 1
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| import numpy as np
from torch.utils.data import Dataset, DataLoader
import time
import polars as pl
# 非内存映射版
class FastCSVBatchDataset(Dataset):
def __init__(self, csv_file, offset_file, batch_size=256):
self.csv_file = csv_file
self.batch_size = batch_size
# 用 Polars 读取偏移文件(多线程)
self.offsets = pl.read_csv(offset_file, has_header=False).to_series().to_numpy()
self.length = len(self.offsets) - 1 # 减去 header
self.num_batches = (self.length + batch_size - 1) // batch_size
# 保存文件路径,不再 mmap
self.csv_file_path = csv_file
def __len__(self):
return self.num_batches
def __getitem__(self, batch_idx):
start_row = batch_idx * self.batch_size
end_row = min(start_row + self.batch_size, self.length)
start_offset = self.offsets[start_row + 1] # +1 跳过 header
# 最后一个 batch 用文件末尾作为 end_offset
if end_row == self.length:
with open(self.csv_file_path, "rb") as f:
f.seek(0, 2) # 移动到文件末尾
end_offset = f.tell()
else:
end_offset = self.offsets[end_row + 1]
# 按偏移读取文件块
with open(self.csv_file_path, "rb") as f:
f.seek(start_offset)
data = f.read(end_offset - start_offset).decode("utf-8")
return data.splitlines() # 保留原来的 decode + splitlines
# ===== 测试 =====
dataset = FastCSVBatchDataset(
"/data/ch/datax.csv",
"/data/ch/datax.offsets",
batch_size=256
)
dataloader = DataLoader(dataset, batch_size=None, shuffle=False, num_workers=8, persistent_workers=True)
num = 1
t0 = time.time()
for batch in dataloader:
if num % 10000 == 0:
print((time.time() - t0) / num)
num += 1
|
内存映射版 VS 非内存映射版:可以看到内存映射文件还是能起到作用的
具体何种情况下有用,何种情况下起副作用,那么就需要更进一步的消融实验了
大致上的相关因素:文件大小、页面切换频率、顺序/乱序读取
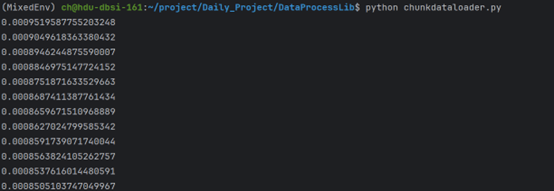
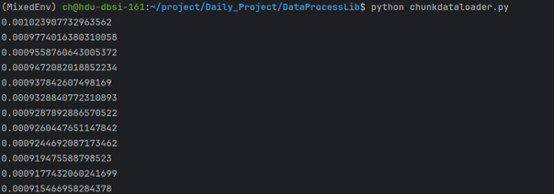
上述代码已经实现异步加载、小批量加载、接近内存读取、同时支持顺序/乱序读取、多进程
其中,异步读取、小批量加载均基于原有组件的功能,依靠将 Batch 视作 Item 实现
接近内存的读取效果主要来源于内存映射文件
且由于内存映射文件的特性,顺序读取的效果会强于乱序读取(页面切换)
顺序读取 VS 乱序读取:(甚至一般情况下顺序读写也应当快于随机读写,毕竟有操作系统优化)
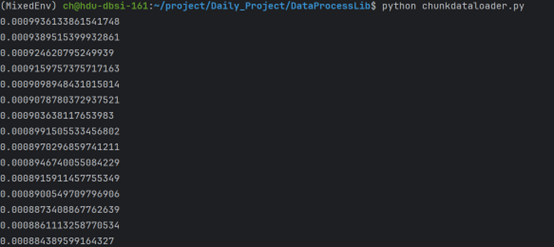
注:
本代码主要可适用于 CSV 格式的行数据文件,不过需要提前生成二进制索引实现随机读写
本代码内,同时采用 Polars 加速该二进制索引文件的读入
Loader 的 batch_size 应当设置为 None,否则无法实现 Batch 的 Item 化
由于直接在 getitem 内实现 Batch 的读取和加载,相比每个样本读取会降低大量的 I/O 启停开销
本处直接使用偏移量读取的方法来替代 For 循环,能够大幅度降低开销
Worker、Batch 的大小可以继续调整,应当还未到达极限
附注:
1.文件格式上,可以考虑转为二进制文件,还能得到更快的速度、同时可支持高效向量化
2.两句处理语句造成的开销占比是最大的,或许存在向量化等更高效的策略
3.或许存在更多的高效方案
