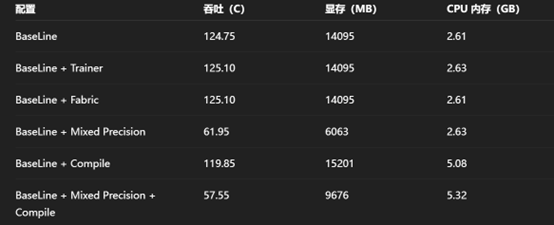
提升主要来源于编译层面的算子融合、代码编译优化,总体可以带来一定幅度的提升
但其具有一定缺点:
首先,每次进程启动都需要预编译和预热,需要一定时间,若训练轮数少、时间短,其加速效果一般
其次,其暂时不支持 Python 3.12 + 版本
最后,针对性价比,个人认为需要看消融结果、继续实验,不同实验效果不同,很难一概而论
总结:
总体可以认为是一个提速的方案,但具体在项目中的应用需要根据具体情况斟酌/消融
其应用方案:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import torch import torch.nn as nn import torch.optim as optim # 定义简单模型 class SimpleNet(nn.Module): def __init__(self): super().__init__() self.net = nn.Sequential( nn.Conv2d(3, 16, 3, padding=1), nn.ReLU(), nn.Conv2d(16, 32, 3, padding=1), nn.ReLU(), nn.AdaptiveAvgPool2d((1, 1)), nn.Flatten(), nn.Linear(32, 10) ) def forward(self, x): return self.net(x) # 构造数据 x = torch.randn(16, 3, 224, 224).cuda() y = torch.randint(0, 10, (16,)).cuda() # 定义模型、优化器、损失函数 model = SimpleNet().cuda() optimizer = optim.Adam(model.parameters()) criterion = nn.CrossEntropyLoss() # 使用 torch.compile 包装模型 compiled_model = torch.compile(model) # 默认后端 'inductor'// 还有其他选项 # 训练一步 for _ in range(5): optimizer.zero_grad() out = compiled_model(x) loss = criterion(out, y) loss.backward() optimizer.step() print("loss:", loss.item())
补注:
1.性价比这一块依旧需要做大量实验来确定效果,如:
显存占用情况和影响因素
内存占用情况和影响因素
提速情况和影响因素(理论上轻量算子多效果好,重量算子多效果一般)
2.编译对算子融合的优化逻辑比较建议加以研究,同时进一步完善算子融合相关的理解
何种算子应当被优化,何种不应当被优化
何种算子理应被优化但并没有被编译优化,这些都是值得研究的
3.编译优化实际上还有很多模式,同时也不止包裹这一种方案,都可以研究、实验,总结影响因素