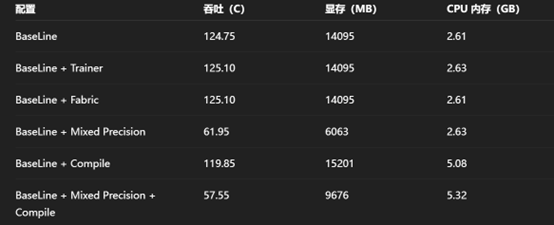
混合精度依旧是目前主推的方案,不仅可以降显存,进一步依靠高 Batch 压榨并行性
同时,还能加速某些算子的计算,在某些计算卡上的加速效果很明显(V100)
同时,还能配合编译、其余加速方案提升计算性能
而上述方案基本不会对训练结果产生过大影响(理论上),基本没有缺点
注:实际加速效果和硬件关系较大
注:BF16 效果上略优于 FP16,但其通用性不高,较早的架构不支持该类型计算
其代码书写格式往往如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| import torch
from torch import nn, optim
from torch.cuda.amp import autocast, GradScaler
# 模型 & 优化器
model = nn.Linear(1024, 1024).cuda()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.MSELoss()
# 混合精度梯度缩放器
scaler = GradScaler()
for epoch in range(10):
for data, target in dataloader:
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
# 前向 + 计算 loss 在 autocast 下执行
with autocast(dtype=torch.float16): # 常见用 torch.float16 或 bfloat16
output = model(data)
loss = criterion(output, target)
# 反向传播时用 scaler
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
|
补注:
1.针对 BP16、FP16 的效果差异仍需调研,需要记录效果以及效果的影响因素
2.针对 FP32、FP16、BP16 做消融实验,确定其对效果的影响,同时确定效果的影响因素
3.针对组合加速方案进行一些实验确认,确认其效果,确认其效果的影响因素
4.显存变动和混合精度的原理上面仍需一定调研,确定其对显存的影响和相关影响因素
