
推理模式
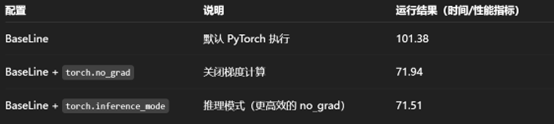
推理过程中,这部分代码是必须加上的,可以显著提升运算效率
其速率提升的来源是梯度计算的禁用
torch.inference_mode 理论上能够带来更大的性能提升,但其使用条件略苛刻
torch.no_grad 基本也能实现相同的性能提升效果,不过没有什么使用限制,比较通用
model.eval() 语句理论上同样可以加速效果,因而往往配合上述两个语句使用
总体属于推理侧的规范操作,必须要写
补注:
1.该两条语句从结果看没有带来显存上面的变化,这点值得继续实验、思考
2.关于训练阶段、验证阶段、推理阶段的显存占用和变化,依旧值得实验和思考(显存相关的知识)
3.model.eval()的效果并没有单独消融,但大致在 5% - 10%,后续可以做相关消融、组合实验
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Ephemeral!